Apache Pulsar 2.8.0
We are very glad to see the Apache Pulsar community has successfully released the 2.8.0 version, which includes a number of exciting upgrades and enhancements. This blog provides a deep dive into the updates from the 2.8.0 release as well as a detailed look at the major Pulsar developments that have helped it evolve into the unified messaging and streaming platform it is today.
Note: The Pulsar community typically releases a major release every 3 months, but it has been 6 months since the release of 2.7.0. We spent more time on 2.8.0 in order to make the transaction API generally available to the Pulsar community.
Release 2.8 Overview
The key features and updates in this release are:
- Exclusive Producer
- Package Management API
- Simplified Client Memory Limit Settings
- Broker Entry Metadata
- New Protobuf Code Generator
- Transactions
Exclusive Producer
By default, the Pulsar producer API provides a "multi-writer" semantic to append messages to a topic. However, there are several use cases that require exclusive access for a single writer, such as ensuring a linear non-interleaved history of messages or providing a mechanism for leader election.
This new feature allows applications to require exclusive producer access in order to achieve a "single-writer" situation. It guarantees that there should be 1 single writer in any combination of errors. If the producer loses its exclusive access, no more messages from it can be published on the topic.
One use case for this feature is the metadata controller in Pulsar Functions. In order to write a single linear history of all the functions metadata updates, the metadata controller requires to elect one leader and that all the "decisions" made by this leader be written on the metadata topic. By leveraging the exclusive producer feature, Pulsar guarantees that the metadata topic contains different segments of updates, one per each successive leader, and there is no interleaving across different leaders. See "PIP-68: Exclusive Producer" for more details.
Package Management API
Since its introduction in version 2.0, the Functions API has become hugely popular among Pulsar users. While it offers many benefits, there are a number of ways to improve the user experience. For example, today, if a function is deployed multiple times, the function package ends up being uploaded multiple times. Also, there is no version management in Pulsar for Functions and IO connectors. The newly introduced package management API provides an easier way to manage the packages for Functions and IO connectors and significantly simplifies the upgrade and rollback processes. Read "Package Management API" for more details.
Simplified Client Memory Limit Settings
Prior to 2.8, there are multiple settings in producers and consumers that allow controlling the sizes of the internal message queues. These settings ultimately control the amount of memory the Pulsar client uses. However, there are few issues with this approach that make it complicated to select an overall configuration that controls the total usage of memory.
For example, the settings are based on the "number of messages", so the expected message size must be adjusted per producer or consumer. If an application has a large (or unknown) number of producers or consumers, it’s very difficult to select an appropriate value for queue sizes. The same is true for topics that have many partitions.
In 2.8, we introduced a new API to set the memory limit. This single memoryLimit setting specifies a maximum amount of memory on a given Pulsar client. The producers and consumers compete for the memory assigned. It ensures the memory used by the Pulsar client will not go beyond the set limit. Read "PIP-74: Pulsar client memory limits" for more details.
Broker Entry Metadata
Pulsar messages define a very comprehensive set of metadata properties. However, to add a new property, the MessageMetadata definition in Pulsar protocol must change to inform both broker and client of the newly introduced property.
But in certain cases, this metadata property might need to be added from the broker side, or need to be retrieved by the broker at a very low cost. To prevent deserializing these properties from the message metadata, we introduced "Broker Entry Metadata" in 2.8.0 to provide a lightweight approach to add additional metadata properties without serializing and deserializing the protobuf-encoded MessageMetadata.
This feature unblocks a new set of capabilities for Pulsar. For example, we can leverage broker entry metadata to generate broker publish time for the messages appended to the Pulsar topic. The other example is to generate a monotonically increasing sequence-id for messages produced to a Pulsar topic. We use this feature in Kafka-on-Pulsar to implement Kafka offset.
New Protobuf Code Generator
Pulsar uses Google Protobuf in order to perform serialization and deserialization of the commands that are exchanged between clients and brokers. Because of the overhead involved with the regular Protobuf implementation, we have been using a modified version of Protobuf 2.4.1. The modifications were done to ensure a more efficient serialization code that used thread local cache for the objects used in the process.
This approach introduced a few issues. For example, the patch to the Protobuf code generator is only based on Protobuf version 2.4.1 and cannot be upgraded to the newer Protobuf versions. In 2.8, we switched the patched Protobuf 2.4.1 to Splunk LightProto as the code generator. The new code generator generates the fastest possible Java code for Protobuf SerDe, is 100% compatible with proto2 definition and wire protocol, and provides zero-copy deserialization using Netty ByteBuf.
Transactions
Prior to Pulsar 2.8, Pulsar only supported exactly-once semantics on single topic through Idempotent Producer. While powerful, Idempotent producer only solves a narrow scope of challenges for exactly-once semantics. For example, there is no atomicity when a producer attempts to produce messages to multiple topics. A publish error can occur when the broker serving one of the topics crashes. If the producer doesn’t retry publishing the message again, it results in some messages being persisted once and others being lost. If the producer retries, it results in some messages being persisted multiple times.
In order to address the remaining challenges described above, we’ve strengthened the Pulsar’s delivery semantics by introducing a Pulsar Transaction API to support atomic writes and acknowledgements across multiple topics. The addition of the Transaction API to Apache Pulsar completes our vision of making Pulsar a complete unified messaging and streaming platform.
Pulsar PMC member, Penghui Li, goes over this functionality in great detail in his recent blog, Exactly-once Semantics with Transactions in Pulsar. You can read it to learn more about the exactly-once semantics support in Pulsar.
Building a Unified Messaging and Streaming Platform with Apache Pulsar
The Evolution of Apache Pulsar
Apache Pulsar is widely adopted by hundreds of companies across the globe, including Splunk, Tencent, Verizon, and Yahoo! JAPAN, just to name a few. Born as a cloud-native distributed messaging system, Apache Pulsar has evolved into a complete messaging and streaming platform for publishing and subscribing, storing, and processing streams of data at scale and in real-time.
Back in 2012 the Yahoo! team was looking for a global, geo-replicated infrastructure that could manage all of Yahoo!’s messaging data. After vetting the messaging and streaming landscape it became clear that existing technologies were not able to serve the need for an event-driven organization. As a result, the team at Yahoo! set out to build its own.
At the time, there were generally two types of systems to handle in-motion data: message queues that handled mission-critical business events in real-time, and streaming systems that handled scalable data pipelines at scale. Companies had to limit their capabilities to one or the other, or they had to adopt multiple different technologies. If they chose multiple technologies, they would end up with a complex infrastructure that often resulted in data segregation and data silos, with one silo for message queues used to build application services and the other silo for streaming systems used to build data services. The figure below illustrates what this can look like.
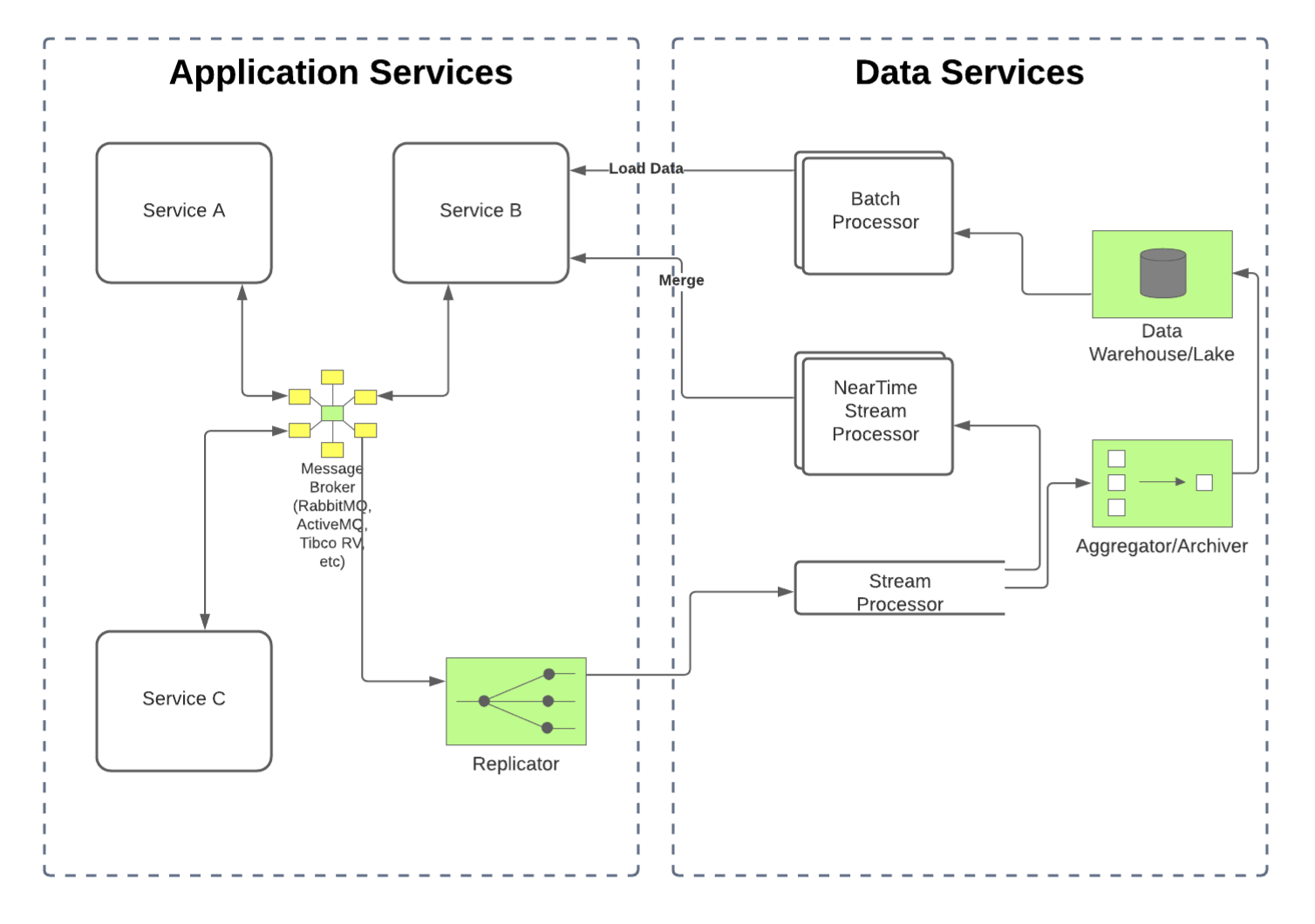
However, with the diversity of data that companies need to process beyond operational data (like log data, click events, etc), coupled with the increase in the number of downstream systems that need access to combined business data and operational data, the system would need to support message queueing and streaming.
Beyond that, companies need an infrastructure platform that would allow them to build all of their applications on top of it, and then have those applications handle in-motion data (messaging and streaming data) by default. This way real-time data infrastructure could be significantly simplified, as illustrated in the diagram below.
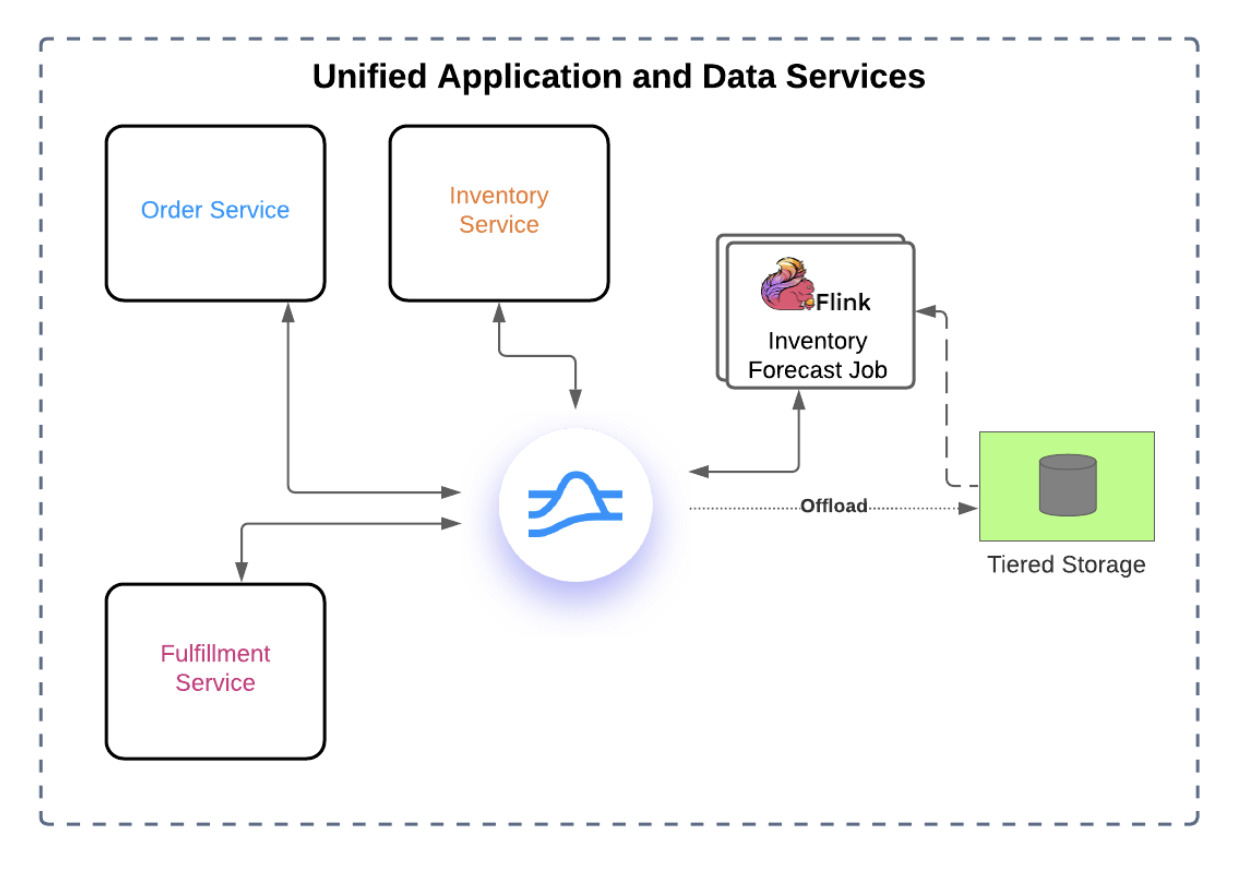
With that vision, the Yahoo! team started working on building a unified messaging and streaming platform for in-motion data. Below is an overview of the key milestones on the Pulsar journey, from inception to today.
Step 1: A scalable storage for streams of data
The journey of Pulsar began with Apache BookKeeper. Apache BookKeeper implements a log-like abstraction for continuous streams and provides the ability to run it at internet-scale with simple write-read log APIs. A log provides a great abstraction for building distributed systems, such as distributed databases and pub-sub messaging. The write APIs are in the form of appends to the log. And the read APIs are in the form of continuous read from a starting offset defined by the readers. The implementation of BookKeeper created the foundation - a scalable log-backed messaging and streaming system.
Step 2: A multi-layered architecture that separates compute from storage.
On top of the scalable log storage, a stateless serving layer was introduced which runs stateless brokers for publishing and consuming messages. This multi-layered architecture separates serving/compute from storage, allowing Pulsar to manage serving and storage in separate layers.
This architecture also ensures instant scalability and higher availability. Both of these factors are extremely important and make Pulsar well-suited for building mission-critical services, such as billing platforms for financial use cases, transaction processing systems for e-commerce and retailers, and real-time risk control systems for financial institutions.
Step 3: Unified messaging model and API
In a modern data architecture, the real-time use cases can typically be categorized into two categories: queueing and streaming. Queueing is typically used for building core business application services while streaming is typically used for building real-time data services such as data pipelines.
To provide one platform able to serve both application and data services required a unified messaging model that integrates queuing and streaming semantics. The Pulsar topics become the source of truth for consumption. Messages can be stored only once on topics, but can be consumed in different ways via different subscriptions. Such unification significantly reduces the complexity of managing and developing messaging and streaming applications.
Step 4: Schema API
Next, a new Pulsar schema registry and a new type-safe producer & consumer API were added. The built-in schema registry enables message producers and consumers on Pulsar topics to coordinate on the structure of the topic’s data through the Pulsar broker itself, without needing an external coordination mechanism. With data schemas, every single piece of data traveling through Pulsar is completely discoverable, enabling you to build systems that can easily adapt as the data changes.
Furthermore, the schema registry keeps track of data compatibility between versions of the schema. As the new schemas are uploaded the registry ensures that new schema versions are able to be read by old consumers. This ensures that Producers cannot break Consumers.
Step 5: Functions and IO API
The next step was to build APIs that made it easy to get data in and out of Pulsar and process it. The goal was to make it easy to build event-driven applications and real-time data pipelines with Apache Pulsar, so you can then process those events when they arrive, no matter where they originated from.
The Pulsar IO API allows you to build real-time streaming data pipelines by plugging various source connectors to get data from external systems into Pulsar and sink connectors to get data from Pulsar into external systems. Today, Pulsar provides several built-in connectors that you can use.
Additionally, StreamNative Hub (a registry of Pulsar connectors) provides dozens of connectors integrated with popular data systems. If the IO API is for building streaming data pipelines, the Functions API is for building event-driven applications and real-time stream processors.
The serverless function concepts were adopted into stream processing and then built the Functions API as a lightweight serverless library that you can write any event processing logic using any language you like. The underlying motivation was to enable your engineering team to write stream processing logic without the operational complexity of running and maintaining yet another cluster.
Step 6: Infinite storage for Pulsar via Tiered Storage
As adoption of Apache Pulsar continued and the amount of data stored in Pulsar increased, users eventually hit a "retention cliff", at which point it became significantly more expensive to store, manage, and retrieve data in Apache BookKeeper. To work around this, operators and application developers typically use an external store like AWS S3 as a sink for long-term storage. This means you lose most of the benefits of Pulsar’s immutable stream and ordering semantics, and instead end up having to manage two different systems with different access patterns.
The introduction of Tiered Storage allows Pulsar to offload the majority of the data to a remote cloud-native storage. This cheaper form of storage readily scales with the volume of data. More importantly, with the addition of Tiered Storage, Pulsar provides the batch storage capabilities needed to support batch processing when integrating with a unified batch and stream processor like Flink. The unified batch and stream processing capabilities integrated with Pulsar enable companies to query real-time streams with historical context quickly and easily, unlocking a unique competitive advantage.
Step 7: Protocol Handler
After introducing tiered storage, Pulsar evolved from a Pub/Sub messaging system into a scalable stream data system that can ingest, store, and process streams of data. However, existing applications written using other messaging protocols such as Kafka, AMQP, MQTT, etc had to be rewritten to adopt Pulsar’s messaging protocol.
The Protocol Handler API further reduces the overhead of adopting Pulsar for building messaging and streaming applications, and allows developers to extend Pulsar capabilities to other messaging domains by leveraging all the benefits provided by Pulsar architecture. This resulted in major collaborations between Pulsar and other industry leaders to develop popular protocol handlers including:
- Kafka-on-Pulsar (KoP), which was launched in March 2020 by OVHCloud and StreamNative.
- AMQP-on-Pulsar (AoP), which was announced in June 2020 by China Mobile and StreamNative.
- MQTT-on-Pulsar (MoP), which was announced in August 2020 by StreamNative.
- RocketMQ-on-Pulsar (RoP), which was launched in May 2021 by Tencent Cloud and StreamNative.
Step 8: Transaction API for exactly-once stream processing
More recently, transactions were added to Apache Pulsar to enable exactly-once semantics for stream processing. This is a fundamental feature that provides a strong guarantee for streaming data transformations, making it easy to build scalable, fault-tolerant, stateful messaging and streaming applications that process streams of data.
Furthermore, the transaction API capabilities are not limited to a given language client. Pulsar’s support for transactional messaging and streaming is primarily a protocol-level capability that can be presented in any language. Such protocol-level capability can be leveraged in all kinds of applications.
Building an ecosystem for unified messaging and streaming
In addition to contributing to the Pulsar technology, the community is also working to build a robust ecosystem to support it. Pulsar’s ability to support a rich ecosystem of pub-sub libraries, connectors, functions, protocol handlers, and integrations with popular query engines will enable Pulsar adopters to streamline workflows and achieve new use cases.
What is Next?
If you are interested in learning more about Pulsar 2.8.0, you can download 2.8.0 and try it out today!
If you want to learn more about how companies have adopted Pulsar, you can sign up for Pulsar Summit NA 2021!
For more information about the Apache Pulsar project and the progress, please visit the official website at https://pulsar.apache.org and follow the project on Twitter @apache_pulsar.