Metadata store and BookKeeper administration
Pulsar relies on two external systems for essential tasks:
- A metadata store is responsible for a wide variety of configuration-related and coordination-related tasks. For new clusters, Oxia is the recommended metadata store; ZooKeeper is also fully supported and is covered on this page. See Configure metadata store for all supported backends.
- BookKeeper is responsible for persistent storage of message data.
This diagram illustrates the role of the metadata store and BookKeeper in a Pulsar cluster:

Each Pulsar cluster consists of one or more message brokers. Each broker relies on an ensemble of bookies.
Oxia
Oxia is the recommended metadata store for new Pulsar clusters. It provides the configuration and coordination services that Pulsar needs, with better scalability for large clusters than ZooKeeper.
To use Oxia as the metadata store:
- Deploy an Oxia cluster and create the target namespace. See the Oxia documentation for deployment instructions.
- Configure Pulsar to use it by setting
metadataStoreUrlandconfigurationMetadataStoreUrl, as described in Configure metadata store.
To move an existing ZooKeeper-based cluster to Oxia without downtime, see Migrate metadata store.
ZooKeeper
ZooKeeper is the traditional metadata store option and ships with the Pulsar binary package. When you use ZooKeeper as the metadata store, each Pulsar instance relies on two separate ZooKeeper quorums.
- Local ZooKeeper operates at the cluster level and provides cluster-specific configuration management and coordination. Each Pulsar cluster needs to have a dedicated ZooKeeper cluster.
- Configuration Store operates at the instance level and provides configuration management for the entire system (and thus across clusters). An independent cluster of machines or the same machines that local ZooKeeper uses can provide the configuration store quorum.
Deploy local ZooKeeper
ZooKeeper manages a variety of essential coordination-related and configuration-related tasks for Pulsar.
To deploy a Pulsar instance, you need to stand up one local ZooKeeper cluster per Pulsar cluster.
To begin, add all ZooKeeper servers to the quorum configuration specified in the conf/zookeeper.conf file. Add a server.N line for each node in the cluster to the configuration, where N is the number of the ZooKeeper node. The following is an example of a three-node cluster:
server.1=zk1.us-west.example.com:2888:3888
server.2=zk2.us-west.example.com:2888:3888
server.3=zk3.us-west.example.com:2888:3888
On each host, you need to specify the node ID in myid file of each node, which is in data/zookeeper folder of each server by default (you can change the file location via the dataDir parameter).
For detailed information on myid and more, see the Multi-server setup guide in the ZooKeeper documentation.
On a ZooKeeper server at zk1.us-west.example.com, for example, you can set the myid value like this:
mkdir -p data/zookeeper
echo 1 > data/zookeeper/myid
On zk2.us-west.example.com the command is echo 2 > data/zookeeper/myid and so on.
Once you add each server to the zookeeper.conf configuration and each server has the appropriate myid entry, you can start ZooKeeper on all hosts (in the background, using nohup) with the pulsar-daemon CLI tool:
bin/pulsar-daemon start zookeeper
Deploy configuration store
The ZooKeeper cluster configured and started up in the section above is a local ZooKeeper cluster that you can use to manage a single Pulsar cluster. In addition to a local cluster, however, a full Pulsar instance also requires a configuration store for handling some instance-level configuration and coordination tasks.
If you deploy a single-cluster instance, you do not need a separate cluster for the configuration store. If, however, you deploy a multi-cluster instance, you need to stand up a separate ZooKeeper cluster for configuration tasks.
Single-cluster Pulsar instance
If your Pulsar instance consists of just one cluster, then you can deploy a configuration store on the same machines as the local ZooKeeper quorum but run on different TCP ports.
To deploy a ZooKeeper configuration store in a single-cluster instance, add the same ZooKeeper servers that the local quorum uses to the configuration file in conf/global_zookeeper.conf using the same method for local ZooKeeper, but make sure to use a different port (2181 is the default for ZooKeeper). The following is an example that uses port 2184 for a three-node ZooKeeper cluster:
clientPort=2184
server.1=zk1.us-west.example.com:2185:2186
server.2=zk2.us-west.example.com:2185:2186
server.3=zk3.us-west.example.com:2185:2186
As before, create the myid files for each server on data/global-zookeeper/myid.
Multi-cluster Pulsar instance
When you deploy a global Pulsar instance, with clusters distributed across different geographical regions, the configuration store serves as a highly available and strongly consistent metadata store that can tolerate failures and partitions spanning whole regions.
The key here is to make sure the ZK quorum members are spread across at least 3 regions and that other regions run as observers.
Again, given the very low expected load on the configuration store servers, you can share the same hosts used for the local ZooKeeper quorum.
For example, you can assume a Pulsar instance with the following clusters us-west, us-east, us-central, eu-central, ap-south. Also you can assume, each cluster has its own local ZK servers named such as zk[1-3].${CLUSTER}.example.com.
In this scenario, you want to pick the quorum participants from a few clusters and let all the others be ZK observers. For example, to form a 7 servers quorum, you can pick 3 servers from us-west, 2 from us-central and 2 from us-east.
This guarantees writing to the configuration store is possible even if one of these regions is unreachable.
The ZK configuration in all the servers looks like below:
clientPort=2184
server.1=zk1.us-west.example.com:2185:2186
server.2=zk2.us-west.example.com:2185:2186
server.3=zk3.us-west.example.com:2185:2186
server.4=zk1.us-central.example.com:2185:2186
server.5=zk2.us-central.example.com:2185:2186
server.6=zk3.us-central.example.com:2185:2186:observer
server.7=zk1.us-east.example.com:2185:2186
server.8=zk2.us-east.example.com:2185:2186
server.9=zk3.us-east.example.com:2185:2186:observer
server.10=zk1.eu-central.example.com:2185:2186:observer
server.11=zk2.eu-central.example.com:2185:2186:observer
server.12=zk3.eu-central.example.com:2185:2186:observer
server.13=zk1.ap-south.example.com:2185:2186:observer
server.14=zk2.ap-south.example.com:2185:2186:observer
server.15=zk3.ap-south.example.com:2185:2186:observer
Additionally, ZK observers need to have:
peerType=observer
Start the service
Once your configuration store configuration is in place, you can start up the service using pulsar-daemon
bin/pulsar-daemon start configuration-store
ZooKeeper configuration
In Pulsar, ZooKeeper configuration is handled by two separate configuration files in the conf directory of your Pulsar installation:
- The
conf/zookeeper.conffile handles the configuration for local ZooKeeper. - The
conf/global-zookeeper.conffile handles the configuration for the configuration store. See parameters for more details.
Configure batching operations
Using the batching operations reduces the remote procedure call (RPC) traffic between the ZooKeeper client and servers. It also reduces the number of write transactions, because each batching operation corresponds to a single ZooKeeper transaction, containing multiple read and write operations.
The following figure demonstrates a basic benchmark of batching read/write operations that can be requested to ZooKeeper in one second:
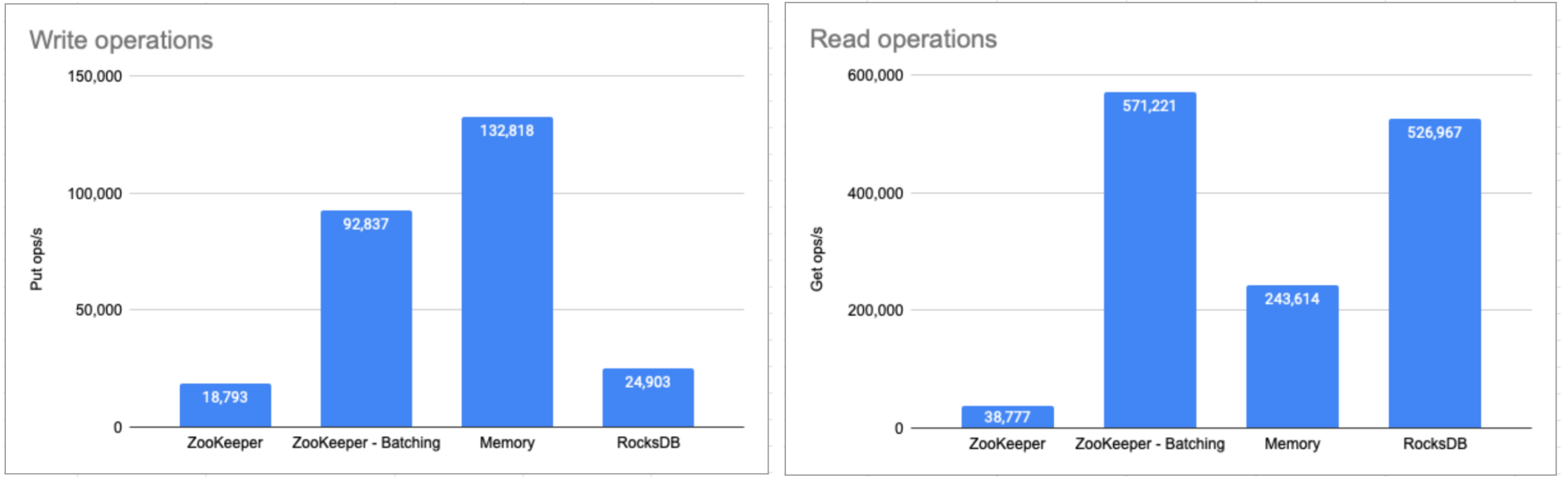
To enable batching operations, set the metadataStoreBatchingEnabled parameter to true on the broker side.
BookKeeper
BookKeeper is a scalable, low-latency persistent log storage service that Pulsar uses to store all durable data. BookKeeper is a distributed write-ahead log WAL system that guarantees read consistency of independent message logs calls ledgers. Individual BookKeeper servers are also called bookies.
To manage message persistence, retention, and expiry in Pulsar, refer to cookbook.
Hardware requirements
Bookie hosts store message data on disk. To provide optimal performance, ensure that the bookies have a suitable hardware configuration. The following are two key dimensions of bookie hardware capacity:
- Disk I/O capacity read/write
- Storage capacity
Message entries written to bookies are always synced to disk before returning an acknowledgment to the Pulsar broker by default. To ensure low write latency, BookKeeper is designed to use multiple devices:
- A journal to ensure durability. For sequential writes, it is critical to have fast fsync operations on bookie hosts. Typically, small and fast solid-state drives (SSDs) should suffice, or hard disk drives (HDDs) with a RAID controller and a battery-backed write cache. Both solutions can reach fsync latency of ~0.4 ms.
- A ledger storage device stores data. Writes happen in the background, so writing I/O is not a big concern. Reads happen sequentially most of the time and the backlog is drained only in case of consumer drain. To store large amounts of data, a typical configuration involves multiple HDDs with a RAID controller.
Configure BookKeeper
You can configure BookKeeper bookies using the conf/bookkeeper.conf configuration file. When you configure each bookie, ensure that the zkServers parameter is set to the connection string for local ZooKeeper of the Pulsar cluster.
The minimum configuration changes required in conf/bookkeeper.conf are as follows:
Set journalDirectory and ledgerDirectories carefully. It is difficult to change them later.
# Change to point to journal disk mount point
journalDirectory=data/bookkeeper/journal
# Point to ledger storage disk mount point
ledgerDirectories=data/bookkeeper/ledgers
# Point to local ZK quorum
zkServers=zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181
#It is recommended to set this parameter. Otherwise, BookKeeper can't start normally in certain environments (for example, Huawei Cloud).
advertisedAddress=
To change the ZooKeeper root path that BookKeeper uses, use zkLedgersRootPath=/MY-PREFIX/ledgers instead of zkServers=localhost:2181/MY-PREFIX.
For more information about BookKeeper, refer to the official BookKeeper docs.
Deploy BookKeeper
BookKeeper provides persistent message storage for Pulsar. Each Pulsar broker has its own cluster of bookies. The BookKeeper cluster shares a local ZooKeeper quorum with the Pulsar cluster.
Start bookies manually
You can start a bookie in the foreground or as a background daemon.
To start a bookie in the foreground, use the bookkeeper CLI tool:
bin/bookkeeper bookie
To start a bookie in the background, use the pulsar-daemon CLI tool:
bin/pulsar-daemon start bookie
You can verify whether the bookie works properly with the bookiesanity command for the BookKeeper shell:
bin/bookkeeper shell bookiesanity
When you use this command, you create a new ledger on the local bookie, write a few entries, read them back and finally delete the ledger.
Decommission bookies cleanly
Before you decommission a bookie, you need to check your environment and meet the following requirements.
-
Ensure the state of your cluster supports decommissioning the target bookie. Check if
EnsembleSize>=Write Quorum>=Ack Quorumistruewith one less bookie. -
Ensure the target bookie is listed after using the
listbookiescommand. -
Ensure that no other process is ongoing (upgrade etc).
And then you can decommission bookies safely. To decommission bookies, complete the following steps.
-
Log in to the bookie node, and check if there are under-replicated ledgers. The decommission command force to replicate the underreplicated ledgers.
bin/bookkeeper shell listunderreplicated -
Stop the bookie by killing the bookie process. Make sure that no liveness/readiness probes setup for the bookies to spin them back up if you deploy it in a Kubernetes environment.
-
Run the decommission command.
- If you have logged in to the node to be decommissioned, you do not need to provide
-bookieid. - If you are running the decommission command for the target bookie node from another bookie node, you should mention the target bookie ID in the arguments for
-bookieidbin/bookkeeper shell decommissionbookieorbin/bookkeeper shell decommissionbookie -bookieid <target bookieid>
- If you have logged in to the node to be decommissioned, you do not need to provide
-
Validate that no ledgers are on the decommissioned bookie.
bin/bookkeeper shell listledgers -bookieid <target bookieid>
You can run the following command to check if the bookie you have decommissioned is listed:
bin/bookkeeper shell listbookies -rw -h
bin/bookkeeper shell listbookies -ro -h
AutoRecovery
BookKeeper AutoRecovery automatically detects unavailable bookies and rereplicated under-replicated ledger fragments to healthy bookies — without manual intervention. For a full explanation of how AutoRecovery works, see the BookKeeper AutoRecovery documentation.
Deploy AutoRecovery
AutoRecovery can run embedded within each bookie process (default) or on dedicated nodes:
- Embedded (default):
autoRecoveryDaemonEnabled=trueinconf/bookkeeper.conf— each bookie runs an AutoRecovery thread alongside normal bookie operations. - Dedicated nodes: Set
autoRecoveryDaemonEnabled=falseon all bookies and run AutoRecovery as a separate process. Recommended for large clusters to isolate recovery I/O from bookie traffic.
To start AutoRecovery as a standalone process:
bin/bookkeeper autorecovery
Or as a background daemon:
bin/pulsar-daemon start autorecovery
Enable and disable AutoRecovery
You can temporarily disable AutoRecovery cluster-wide during planned maintenance and re-enable it afterward:
# Disable AutoRecovery
bin/bookkeeper shell autorecovery -disable
# Enable AutoRecovery
bin/bookkeeper shell autorecovery -enable
# Check current status
bin/bookkeeper shell autorecovery -status
Pulsar-specific configuration
Set lostBookieRecoveryDelay in conf/bookkeeper.conf to a value greater than 0 (for example, 60 seconds) in production clusters that undergo rolling restarts. This prevents AutoRecovery from triggering unnecessary rereplication for bookies that are only temporarily unavailable.
To enable Prometheus metrics on a bookie or AutoRecovery node, set the following in conf/bookkeeper.conf:
statsProviderClass=org.apache.pulsar.metrics.prometheus.bookkeeper.PrometheusMetricsProvider
This Pulsar-specific stats provider class is required since Pulsar 4.2.0 / 4.0.10. See the Pulsar 4.0.10 release notes for details.
BookKeeper persistence policies
In Pulsar, you can set persistence policies at the namespace level, which determines how BookKeeper handles persistent storage of messages. Policies determine four things:
- Ensemble (E) size, Number of bookies to use for storing entries in a ledger.
- Write quorum (Qw) size, Replication factor for storing entries (messages) in a ledger.
- Ack quorum (Qa) size, Number of guaranteed copies (acks to wait for before a write is considered completed).
- The throttling rate for mark-delete operations.
Set persistence policies
You can set persistence policies for BookKeeper at the namespace level.
- Pulsar-admin
- REST API
- Java
Use the set-persistence subcommand and specify a namespace as well as any policies that you want to apply. The available flags are:
| Flag | Description | Default |
|---|---|---|
-e, --bookkeeper-ensemble | Ensemble (E) size, Number of bookies to use for storing entries in a ledger. | 0 |
-w, --bookkeeper-write-quorum | Write quorum (Qw) size, Replication factor for storing entries (messages) in a ledger. | 0 |
-a, --bookkeeper-ack-quorum | Ack quorum (Qa) size, Number of guaranteed copies (acks to wait for before a write is considered completed) | 0 |
-r, --ml-mark-delete-max-rate | Throttling rate for mark-delete operations (0 means no throttle) | 0 |
Please notice that sticky reads enabled by bookkeeperEnableStickyReads=true are not used unless ensemble size (E) equals write quorum (Qw) size. Sticky reads improve the efficiency of the Bookkeeper read ahead cache when all reads for a single ledger are sent to a single bookie.
Some rules for choosing the values:
| Rule | Description |
|---|---|
| E >= Qw >= Qa | Ensemble size must be larger or equal than write quorum size, write quorum size must be larger or equal than ack quorum size. |
| Max bookie failures = Qa-1, | This rule must be fulfilled if data durability is desired in case of bookie failures. To safely tolerate at least one bookie failure at a time in the ensemble, Qa must be set to a value at least 2. |
| E == Qw | Sticky reads enabled by bookkeeperEnableStickyReads=true aren't used unless ensemble size (E) equals write quorum (Qw) size. |
The following is an example:
pulsar-admin namespaces set-persistence my-tenant/my-ns \
--bookkeeper-ensemble 3 \
--bookkeeper-write-quorum 3 \
--bookkeeper-ack-quorum 3
Short example:
pulsar-admin namespaces set-persistence my-tenant/my-ns -e 3 -w 3 -a 3
// The following must be true: bkEnsemble >= bkWriteQuorum >= bkAckQuorum
// Please notice that sticky reads cannot be used unless bkEnsemble == bkWriteQuorum.
int bkEnsemble = 3;
int bkWriteQuorum = 3;
int bkAckQuorum = 3;
double markDeleteRate = 0.7;
PersistencePolicies policies =
new PersistencePolicies(bkEnsemble, bkWriteQuorum, bkAckQuorum, markDeleteRate);
admin.namespaces().setPersistence(namespace, policies);
List persistence policies
You can see which persistence policy currently applies to a namespace.
- Pulsar-admin
- REST API
- Java
Use the get-persistence subcommand and specify the namespace.
The following is an example:
pulsar-admin namespaces get-persistence my-tenant/my-ns
{
"bookkeeperEnsemble": 1,
"bookkeeperWriteQuorum": 1,
"bookkeeperAckQuorum", 1,
"managedLedgerMaxMarkDeleteRate": 0
}
PersistencePolicies policies = admin.namespaces().getPersistence(namespace);