Pulsar Functions overview
Pulsar Functions are lightweight compute processes that
- consume messages from one or more Pulsar topics,
- apply a user-supplied processing logic to each message,
- publish the results of the computation to another topic
Here's an example Pulsar Function for Java (using the native interface):
import java.util.Function;
public class ExclamationFunction implements Function<String, String> {
@Override
public String apply(String input) { return String.format("%s!", input); }
}
Here's an equivalent function in Python (also using the native interface):
def process(input):
return "{0}!".format(input)
Functions are executed each time a message is published to the input topic. If a function is listening on the topic tweet-stream, for example, then the function would be run each time a message is published to that topic.
Goals
The core goal behind Pulsar Functions is to enable you to easily create processing logic of any level of complexity without needing to deploy a separate neighboring system (such as Apache Storm, Apache Heron, Apache Flink, etc.). Pulsar Functions is essentially ready-made compute infrastructure at your disposal as part of your Pulsar messaging system. This core goal is tied to a series of other goals:
- Developer productivity (language-native vs. Pulsar Functions SDK functions)
- Easy troubleshooting
- Operational simplicity (no need for an external processing system)
Inspirations
The Pulsar Functions feature was inspired by (and takes cues from) several systems and paradigms:
- Stream processing engines such as Apache Storm, Apache Heron, and Apache Flink
- "Serverless" and "Function as a Service" (FaaS) cloud platforms like Amazon Web Services Lambda, Google Cloud Functions, and Azure Cloud Functions
Pulsar Functions could be described as
- Lambda-style functions that are
- specifically designed to use Pulsar as a message bus
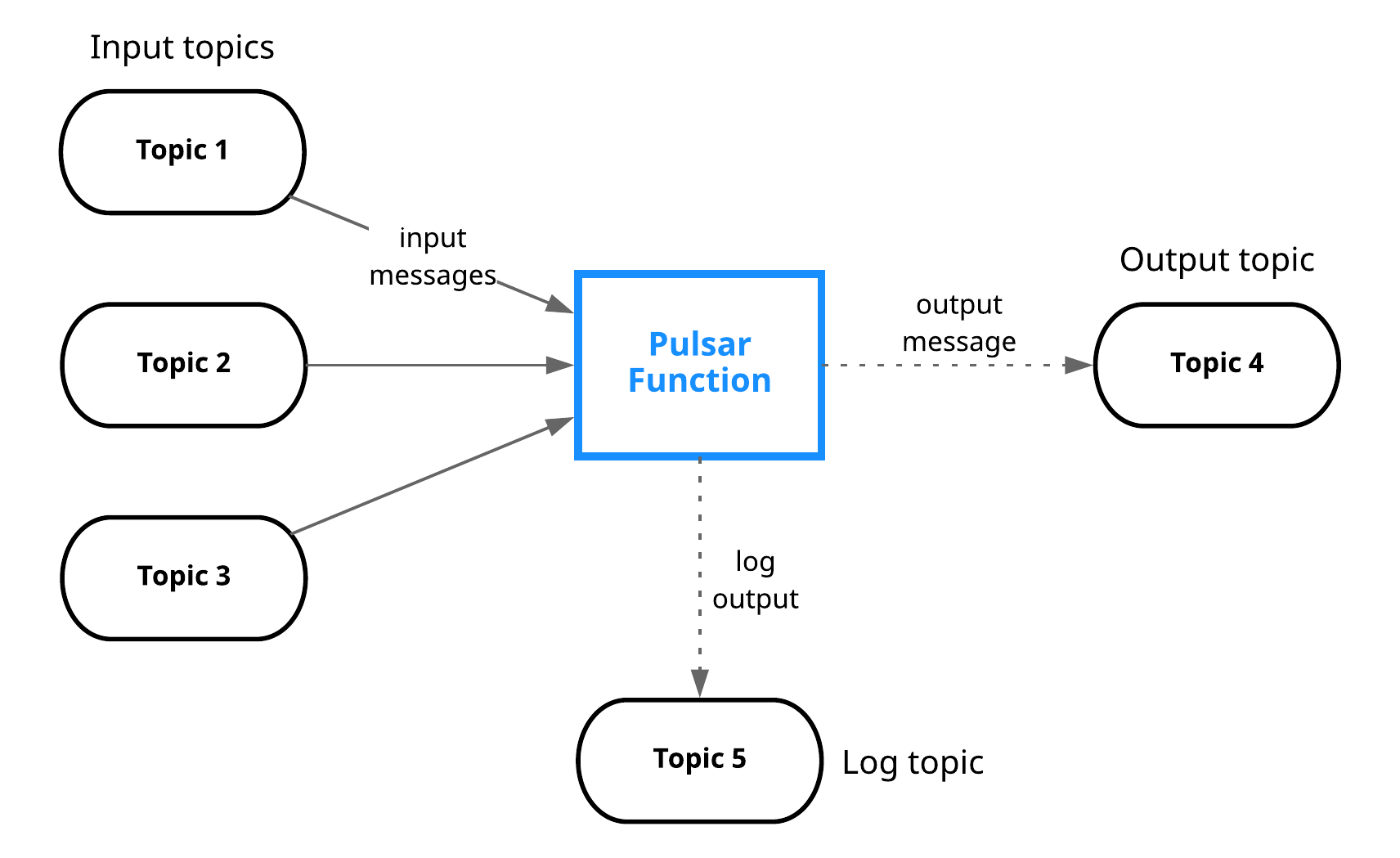
Programming model
The core programming model behind Pulsar Functions is very simple:
- Functions receive messages from one or more input topics. Every time a message is received, the function can do a variety of things:
- Apply some processing logic to the input and write output to:
- An output topic in Pulsar
- Apache BookKeeper
- Write logs to a log topic (potentially for debugging purposes)
- Increment a counter
Word count example
If you were to implement the classic word count example using Pulsar Functions, it might look something like this:
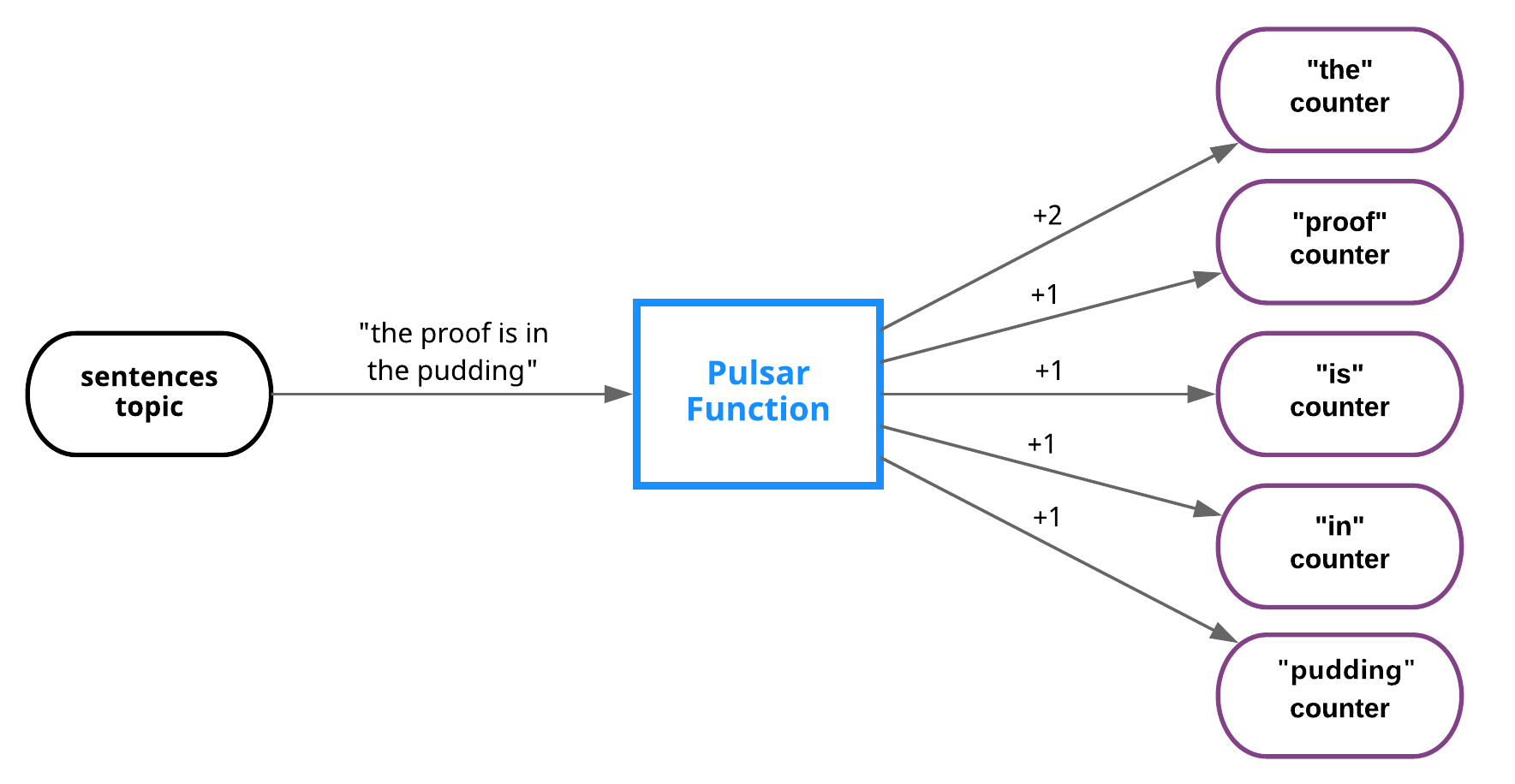
If you were writing the function in Java using the Pulsar Functions SDK for Java, you could write the function like this...
package org.example.functions;
import org.apache.pulsar.functions.api.Context;
import org.apache.pulsar.functions.api.Function;
import java.util.Arrays;
public class WordCountFunction implements Function<String, Void> {
// This function is invoked every time a message is published to the input topic
@Override
public Void process(String input, Context context) {
Arrays.asList(input.split(" ")).forEach(word -> {
String counterKey = word.toLowerCase();
context.incrCounter(counterKey, 1)
});
return null;
}
}
...and then deploy it in your Pulsar cluster using the command line like this:
$ bin/pulsar-admin functions create \
--jar target/my-jar-with-dependencies.jar \
--classname org.example.functions.WordCountFunction \
--tenant public \
--namespace default \
--name word-count \
--inputs persistent://public/default/sentences \
--output persistent://public/default/count
Content-based routing example
The use cases for Pulsar Functions are essentially endless, but let's dig into a more sophisticated example that involves content-based routing.
Imagine a function that takes items (strings) as input and publishes them to either a fruits or vegetables topic, depending on the item. Or, if an item is neither a fruit nor a vegetable, a warning is logged to a log topic. Here's a visual representation:
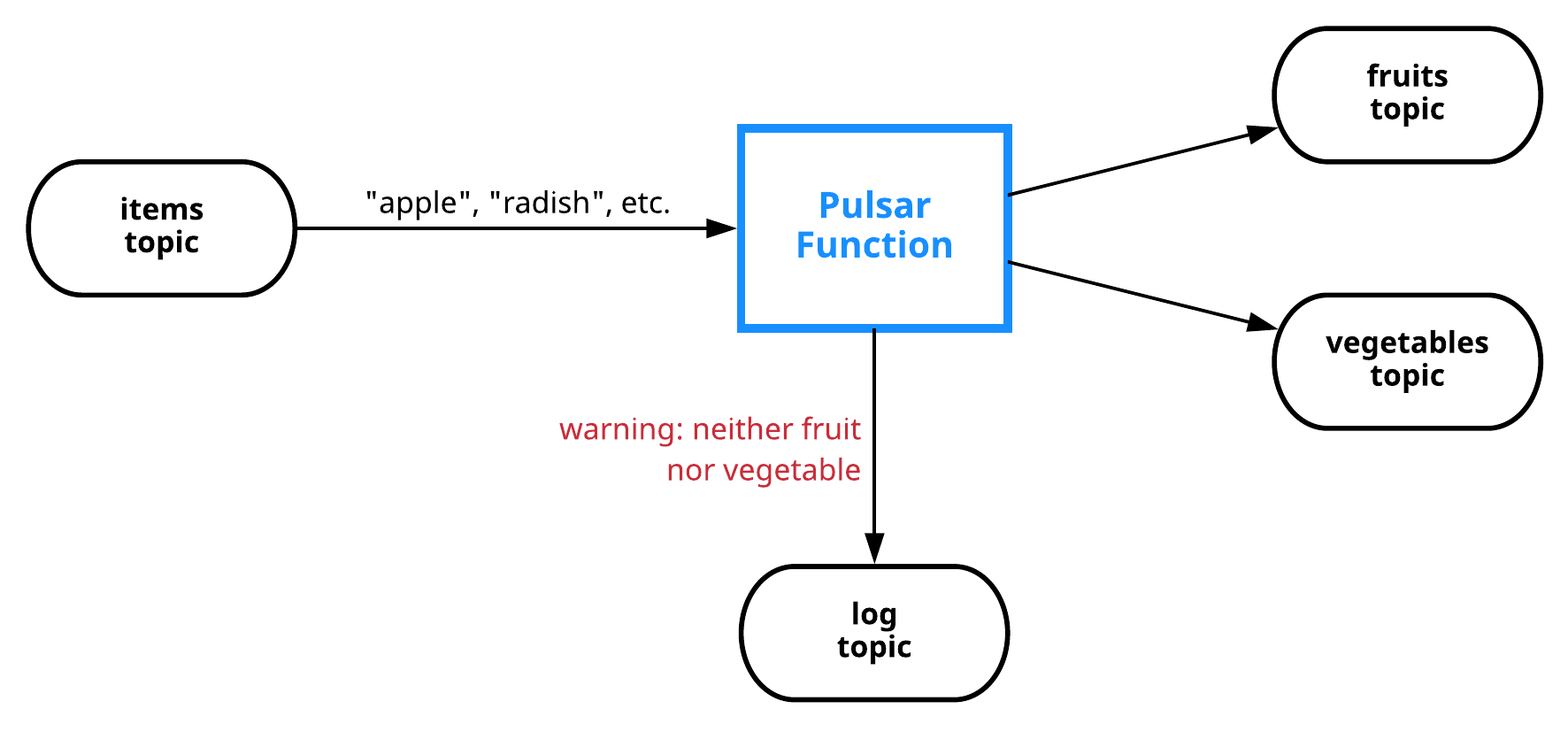
If you were implementing this routing functionality in Python, it might look something like this:
from pulsar import Function
class RoutingFunction(Function):
def __init__(self):
self.fruits_topic = "persistent://public/default/fruits"
self.vegetables_topic = "persistent://public/default/vegetables"
@staticmethod
def is_fruit(item):
return item in ["apple", "orange", "pear", "other fruits..."]
@staticmethod
def is_vegetable(item):
return item in ["carrot", "lettuce", "radish", "other vegetables..."]
def process(self, item, context):
if self.is_fruit(item):
context.publish(self.fruits_topic, item)
elif self.is_vegetable(item):
context.publish(self.vegetables_topic, item)
else:
warning = "The item {0} is neither a fruit nor a vegetable".format(item)
context.get_logger().warn(warning)
Command-line interface
Pulsar Functions are managed using the pulsar-admin CLI tool (in particular the functions command). Here's an example command that would run a function in local run mode:
$ bin/pulsar-functions localrun \
--inputs persistent://public/default/test_src \
--output persistent://public/default/test_result \
--jar examples/api-examples.jar \
--classname org.apache.pulsar.functions.api.examples.ExclamationFunction
Fully Qualified Function Name (FQFN)
Each Pulsar Function has a Fully Qualified Function Name (FQFN) that consists of three elements: the function's tenant, namespace, and function name. FQFN's look like this:
tenant/namespace/name
FQFNs enable you to, for example, create multiple functions with the same name provided that they're in different namespaces.
Configuration
Pulsar Functions can be configured in two ways:
- Via command-line arguments passed to the
pulsar-admin functionsinterface - Via YAML configuration files
If you're supplying a YAML configuration, you must specify a path to the file on the command line. Here's an example:
$ bin/pulsar-admin functions create \
--function-config-file ./my-function.yaml
And here's an example my-function.yaml file:
name: my-function
tenant: public
namespace: default
jar: ./target/my-functions.jar
className: org.example.pulsar.functions.MyFunction
inputs:
- persistent://public/default/test_src
output: persistent://public/default/test_result
You can also mix and match configuration methods by specifying some function attributes via the CLI and others via YAML configuration.
Supported languages
Pulsar Functions can currently be written in Java and Python. Support for additional languages is coming soon.
The Pulsar Functions API
The Pulsar Functions API enables you to create processing logic that is:
- Type safe. Pulsar Functions can process raw bytes or more complex, application-specific types.
- Based on SerDe (Serialization/Deserialization). A variety of types are supported "out of the box" but you can also create your own custom SerDe logic.
Function context
Each Pulsar Function created using the Pulsar Functions SDK has access to a context object that both provides:
- A wide variety of information about the function, including:
- The name of the function
- The tenant and namespace of the function
- User-supplied configuration values
- Special functionality, including:
Language-native functions
Both Java and Python support writing "native" functions, i.e. Pulsar Functions with no dependencies.
The benefit of native functions is that they don't have any dependencies beyond what's already available in Java/Python "out of the box." The downside is that they don't provide access to the function's context, which is necessary for a variety of functionality, including logging, user configuration, and more.
The Pulsar Functions SDK
If you'd like a Pulsar Function to have access to a context object, you can use the Pulsar Functions SDK, available for both Java and Pythnon.
Java
Here's an example Java function that uses information about its context:
import org.apache.pulsar.functions.api.Context;
import org.apache.pulsar.functions.api.Function;
import org.slf4j.Logger;
public class ContextAwareFunction implements Function<String, Void> {
@Override
public Void process(String input, Context, context) {
Logger LOG = context.getLogger();
String functionTenant = context.getTenant();
String functionNamespace = context.getNamespace();
String functionName = context.getName();
LOG.info("Function tenant/namespace/name: {}/{}/{}", functionTenant, functionNamespace, functionName);
return null;
}
}
Python
Here's an example Python function that uses information about its context:
from pulsar import Function
class ContextAwareFunction(Function):
def process(self, input, context):
log = context.get_logger()
function_tenant = context.get_function_tenant()
function_namespace = context.get_function_namespace()
function_name = context.get_function_name()
log.info("Function tenant/namespace/name: {0}/{1}/{2}".format(function_tenant, function_namespace, function_name))
Deployment
The Pulsar Functions feature was built to support a variety of deployment options. At the moment, there are two ways to run Pulsar Functions:
| Deployment mode | Description |
|---|---|
| Local run mode | The function runs in your local environment, for example on your laptop Cluster mode |
Local run mode
If you run a Pulsar Function in local run mode, it will run on the machine from which the command is run (this could be your laptop, an AWS EC2 instance, etc.). Here's an example localrun command:
$ bin/pulsar-admin functions localrun \
--py myfunc.py \
--classname myfunc.SomeFunction \
--inputs persistent://public/default/input-1 \
--output persistent://public/default/output-1
By default, the function will connect to a Pulsar cluster running on the same machine, via a local broker service URL of pulsar://localhost:6650. If you'd like to use local run mode to run a function but connect it to a non-local Pulsar cluster, you can specify a different broker URL using the --brokerServiceUrl flag. Here's an example:
$ bin/pulsar-admin functions localrun \
--broker-service-url pulsar://my-cluster-host:6650 \
# Other function parameters
Cluster run mode
When you run a Pulsar Function in cluster mode, the function code will be uploaded to a Pulsar broker and run alongside the broker rather than in your local environment. You can run a function in cluster mode using the create command. Here's an example:
$ bin/pulsar-admin functions create \
--py myfunc.py \
--classname myfunc.SomeFunction \
--inputs persistent://public/default/input-1 \
--output persistent://public/default/output-1
This command will upload myfunc.py to Pulsar, which will use the code to start one or more instances of the function.
Parallelism
By default, only one instance of a Pulsar Function runs when you create and run it in cluster run mode. You can also, however, run multiple instances in parallel. You can specify the number of instances when you create the function, or update an existing single-instance function with a new parallelism factor.
This command, for example, would create and run a function with a parallelism of 5 (i.e. 5 instances):
$ bin/pulsar-admin functions create \
--name parallel-fun \
--tenant public \
--namespace default \
--py func.py \
--classname func.ParallelFunction \
--parallelism 5
Function instance resources
When you run Pulsar Functions in cluster run mode, you can specify the resources that are assigned to each function instance:
| Resource | Specified as... | Runtimes |
|---|---|---|
| CPU | The number of cores | Docker (coming soon) |
| RAM | The number of bytes | Process, Docker |
| Disk space | The number of bytes | Docker |
Here's an example function creation command that allocates 8 cores, 8 GB of RAM, and 10 GB of disk space to a function:
$ bin/pulsar-admin functions create \
--jar target/my-functions.jar \
--classname org.example.functions.MyFunction \
--cpu 8 \
--ram 8589934592 \
--disk 10737418240
For more information on resources, see the Deploying and Managing Pulsar Functions documentation.
Logging
Pulsar Functions created using the Pulsar Functions SDK can send logs to a log topic that you specify as part of the function's configuration. The function created using the command below, for example, would produce all logs on the persistent://public/default/my-func-1-log topic:
$ bin/pulsar-admin functions create \
--name my-func-1 \
--log-topic persistent://public/default/my-func-1-log \
# Other configs
Here's an example Java function that logs at different log levels based on the function's input:
public class LoggerFunction implements Function<String, Void> {
@Override
public Void process(String input, Context context) {
Logger LOG = context.getLogger();
if (input.length() <= 100) {
LOG.info("This string has a length of {}", input);
} else {
LOG.warn("This string is getting too long! It has {} characters", input);
}
}
}
User configuration
Pulsar Functions can be passed arbitrary key-values via the command line (both keys and values must be strings). This set of key-values is called the functions user configuration. User configurations must consist of JSON strings.
Here's an example of passing a user configuration to a function:
$ bin/pulsar-admin functions create \
--user-config '{"key-1":"value-1","key-2","value-2"}' \
# Other configs
Here's an example of a function that accesses that config map:
public class ConfigMapFunction implements Function<String, Void> {
@Override
public Void process(String input, Context context) {
String val1 = context.getUserConfigValue("key1").get();
String val2 = context.getUserConfigValue("key2").get();
context.getLogger().info("The user-supplied values are {} and {}", val1, val2);
return null;
}
}
Triggering Pulsar Functions
Pulsar Functions running in cluster mode can be triggered via the command line. With triggering you can easily pass a specific value to a function and get the function's return value without needing to worry about creating a client, sending a message to the right input topic, etc. Triggering can be very useful for---but is by no means limited to---testing and debugging purposes.
Triggering a function is ultimately no different from invoking a function by producing a message on one of the function's input topics. The
pulsar-admin functions triggercommand is essentially a convenient mechanism for sending messages to functions without needing to use thepulsar-clienttool or a language-specific client library.
Let's take an example Pulsar Function written in Python (using the native interface) that simply reverses string inputs:
def process(input):
return input[::-1]
If that function were running in a Pulsar cluster, it could be triggered like this:
$ bin/pulsar-admin functions trigger \
--tenant public \
--namespace default \
--name reverse-func \
--trigger-value "snoitcnuf raslup ot emoclew"
That should return welcome to pulsar functions as the console output.
Instead of passing in a string via the CLI, you can also trigger a Pulsar Function with the contents of a file using the
--triggerFileflag.
Processing guarantees
The Pulsar Functions feature provides three different messaging semantics that you can apply to any function:
| Delivery semantics | Description |
|---|---|
| At-most-once delivery | Each message that is sent to the function will most likely be processed but also may not be (hence the "at most") |
| At-least-once delivery | Each message that is sent to the function could be processed more than once (hence the "at least") |
| Effectively-once delivery | Each message that is sent to the function will have one output associated with it |
This command, for example, would run a function in cluster mode with effectively-once guarantees applied:
$ bin/pulsar-admin functions create \
--name my-effectively-once-function \
--processing-guarantees EFFECTIVELY_ONCE \
# Other function configs
Metrics
Pulsar Functions that use the Pulsar Functions SDK can publish metrics to Pulsar. For more information, see Metrics for Pulsar Functions.
State storage
Pulsar Functions use Apache BookKeeper as a state storage interface. All Pulsar installations, including local standalone installations, include a deployment of BookKeeper bookies.