Understand schema
This chapter explains the basic concepts of Pulsar schema, focuses on the topics of particular importance, and provides additional background.
SchemaInfo
Pulsar schema is defined in a data structure called SchemaInfo.
The SchemaInfo is stored and enforced on a per-topic basis and cannot be stored at the namespace or tenant level.
A SchemaInfo consists of the following fields:
| Field | Description |
|---|---|
name | Schema name (a string). |
type | Schema type, which determines how to interpret the schema data. |
schema(payload) | Schema data, which is a sequence of 8-bit unsigned bytes and schema-type specific. |
properties | It is a user defined properties as a string/string map. Applications can use this bag for carrying any application specific logics. Possible properties might be the Git hash associated with the schema, an environment string like dev or prod. |
Example
This is the SchemaInfo of a string.
{
"name": "test-string-schema",
"type": "STRING",
"schema": "",
"properties": {}
}
Schema type
Pulsar supports various schema types, which are mainly divided into two categories:
-
Primitive type
-
Complex type
Primitive type
Currently, Pulsar supports the following primitive types:
| Primitive Type | Description |
|---|---|
BOOLEAN | A binary value |
INT8 | A 8-bit signed integer |
INT16 | A 16-bit signed integer |
INT32 | A 32-bit signed integer |
INT64 | A 64-bit signed integer |
FLOAT | A single precision (32-bit) IEEE 754 floating-point number |
DOUBLE | A double-precision (64-bit) IEEE 754 floating-point number |
BYTES | A sequence of 8-bit unsigned bytes |
STRING | A Unicode character sequence |
TIMESTAMP (DATE, TIME) | A logic type represents a specific instant in time with millisecond precision. It stores the number of milliseconds since January 1, 1970, 00:00:00 GMT as an INT64 value |
| INSTANT | A single instantaneous point on the time-line with nanoseconds precision |
| LOCAL_DATE | An immutable date-time object that represents a date, often viewed as year-month-day |
| LOCAL_TIME | An immutable date-time object that represents a time, often viewed as hour-minute-second. Time is represented to nanosecond precision. |
| LOCAL_DATE_TIME | An immutable date-time object that represents a date-time, often viewed as year-month-day-hour-minute-second |
For primitive types, Pulsar does not store any schema data in SchemaInfo. The type in SchemaInfo is used to determine how to serialize and deserialize the data.
Some of the primitive schema implementations can use properties to store implementation-specific tunable settings. For example, a string schema can use properties to store the encoding charset to serialize and deserialize strings.
The conversions between Pulsar schema types and language-specific primitive types are as below.
| Schema Type | Java Type | Python Type | Go Type |
|---|---|---|---|
| BOOLEAN | boolean | bool | bool |
| INT8 | byte | int8 | |
| INT16 | short | int16 | |
| INT32 | int | int32 | |
| INT64 | long | int64 | |
| FLOAT | float | float | float32 |
| DOUBLE | double | float | float64 |
| BYTES | byte[], ByteBuffer, ByteBuf | bytes | []byte |
| STRING | string | str | string |
| TIMESTAMP | java.sql.Timestamp | ||
| TIME | java.sql.Time | ||
| DATE | java.util.Date | ||
| INSTANT | java.time.Instant | ||
| LOCAL_DATE | java.time.LocalDate | ||
| LOCAL_TIME | java.time.LocalTime | ||
| LOCAL_DATE_TIME | java.time.LocalDateTime |
Example
This example demonstrates how to use a string schema.
-
Create a producer with a string schema and send messages.
Producer<String> producer = client.newProducer(Schema.STRING).create();producer.newMessage().value("Hello Pulsar!").send(); -
Create a consumer with a string schema and receive messages.
Consumer<String> consumer = client.newConsumer(Schema.STRING).subscribe();consumer.receive();
Complex type
Currently, Pulsar supports the following complex types:
| Complex Type | Description |
|---|---|
keyvalue | Represents a complex type of a key/value pair. |
struct | Supports AVRO, JSON, and Protobuf. |
keyvalue
Keyvalue schema helps applications define schemas for both key and value.
For SchemaInfo of keyvalue schema, Pulsar stores the SchemaInfo of key schema and the SchemaInfo of value schema together.
Pulsar provides two methods to encode a key/value pair in messages:
-
INLINE -
SEPARATED
Users can choose the encoding type when constructing the key/value schema.
INLINE
Key/value pairs will be encoded together in the message payload.
SEPARATED
Key will be encoded in the message key and the value will be encoded in the message payload.
Example
This example shows how to construct a key/value schema and then use it to produce and consume messages.
-
Construct a key/value schema with
INLINEencoding type.Schema<KeyValue<Integer, String>> kvSchema = Schema.KeyValue(Schema.INT32,Schema.STRING,KeyValueEncodingType.INLINE); -
Optionally, construct a key/value schema with
SEPARATEDencoding type.Schema<KeyValue<Integer, String>> kvSchema = Schema.KeyValue(Schema.INT32,Schema.STRING,KeyValueEncodingType.SEPARATED); -
Produce messages using a key/value schema.
Schema<KeyValue<Integer, String>> kvSchema = Schema.KeyValue(Schema.INT32,Schema.STRING,KeyValueEncodingType.SEPARATED);Producer<KeyValue<Integer, String>> producer = client.newProducer(kvSchema).topic(TOPIC).create();final int key = 100;final String value = "value-100";// send the key/value messageproducer.newMessage().value(new KeyValue(key, value)).send(); -
Consume messages using a key/value schema.
Schema<KeyValue<Integer, String>> kvSchema = Schema.KeyValue(Schema.INT32,Schema.STRING,KeyValueEncodingType.SEPARATED);Consumer<KeyValue<Integer, String>> consumer = client.newConsumer(kvSchema)....topic(TOPIC).subscriptionName(SubscriptionName).subscribe();// receive key/value pairMessage<KeyValue<Integer, String>> msg = consumer.receive();KeyValue<Integer, String> kv = msg.getValue();
struct
Pulsar uses Avro Specification to declare the schema definition for struct schema.
This allows Pulsar:
-
to use same tools to manage schema definitions
-
to use different serialization/deserialization methods to handle data
There are two methods to use struct schema:
-
static -
generic
static
You can predefine the struct schema, and it can be a POJO in Java, a struct in Go, or classes generated by Avro or Protobuf tools.
Example
Pulsar gets the schema definition from the predefined struct using an Avro library. The schema definition is the schema data stored as a part of the SchemaInfo.
-
Create the User class to define the messages sent to Pulsar topics.
public class User {String name;int age;} -
Create a producer with a
structschema and send messages.Producer<User> producer = client.newProducer(Schema.AVRO(User.class)).create();producer.newMessage().value(User.builder().userName("pulsar-user").userId(1L).build()).send(); -
Create a consumer with a
structschema and receive messagesConsumer<User> consumer = client.newConsumer(Schema.AVRO(User.class)).subscribe();User user = consumer.receive();
generic
Sometimes applications do not have pre-defined structs, and you can use this method to define schema and access data.
You can define the struct schema using the GenericSchemaBuilder, generate a generic struct using GenericRecordBuilder and consume messages into GenericRecord.
Example
-
Use
RecordSchemaBuilderto build a schema.RecordSchemaBuilder recordSchemaBuilder = SchemaBuilder.record("schemaName");recordSchemaBuilder.field("intField").type(SchemaType.INT32);SchemaInfo schemaInfo = recordSchemaBuilder.build(SchemaType.AVRO);Producer<GenericRecord> producer = client.newProducer(Schema.generic(schemaInfo)).create(); -
Use
RecordBuilderto build the struct records.producer.newMessage().value(schema.newRecordBuilder().set("intField", 32).build()).send();
Auto Schema
If you don't know the schema type of a Pulsar topic in advance, you can use AUTO schema to produce or consume generic records to or from brokers.
| Auto Schema Type | Description |
|---|---|
AUTO_PRODUCE | This is useful for transferring data from a producer to a Pulsar topic that has a schema. |
AUTO_CONSUME | This is useful for transferring data from a Pulsar topic that has a schema to a consumer. |
AUTO_PRODUCE
AUTO_PRODUCE schema helps a producer validate whether the bytes sent by the producer is compatible with the schema of a topic.
Example
Suppose that:
-
You have a producer processing messages from a Kafka topic K.
-
You have a Pulsar topic P, and you do not know its schema type.
-
Your application reads the messages from K and writes the messages to P.
In this case, you can use AUTO_PRODUCE to verify whether the bytes produced by K can be sent to P or not.
Produce<byte[]> pulsarProducer = client.newProducer(Schema.AUTO_PRODUCE())
…
.create();
byte[] kafkaMessageBytes = … ;
pulsarProducer.produce(kafkaMessageBytes);
AUTO_CONSUME
AUTO_CONSUME schema helps a Pulsar topic validate whether the bytes sent by a Pulsar topic is compatible with a consumer, that is, the Pulsar topic deserializes messages into language-specific objects using the SchemaInfo retrieved from broker-side.
Currently, AUTO_CONSUME only supports AVRO and JSON schemas. It deserializes messages into GenericRecord.
Example
Suppose that:
-
You have a Pulsar topic P.
-
You have a consumer (for example, MySQL) receiving messages from the topic P.
-
Your application reads the messages from P and writes the messages to MySQL.
In this case, you can use AUTO_CONSUME to verify whether the bytes produced by P can be sent to MySQL or not.
Consumer<GenericRecord> pulsarConsumer = client.newConsumer(Schema.AUTO_CONSUME())
…
.subscribe();
Message<GenericRecord> msg = consumer.receive() ;
GenericRecord record = msg.getValue();
Schema version
Each SchemaInfo stored with a topic has a version. Schema version manages schema changes happening within a topic.
Messages produced with a given SchemaInfo is tagged with a schema version, so when a message is consumed by a Pulsar client, the Pulsar client can use the schema version to retrieve the corresponding SchemaInfo and then use the SchemaInfo to deserialize data.
Schemas are versioned in succession. Schema storage happens in a broker that handles the associated topics so that version assignments can be made.
Once a version is assigned/fetched to/for a schema, all subsequent messages produced by that producer are tagged with the appropriate version.
Example
The following example illustrates how the schema version works.
Suppose that a Pulsar Java client created using the code below attempts to connect to Pulsar and begins to send messages:
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
Producer<SensorReading> producer = client.newProducer(JSONSchema.of(SensorReading.class))
.topic("sensor-data")
.sendTimeout(3, TimeUnit.SECONDS)
.create();
The table below lists the possible scenarios when this connection attempt occurs and what happens in each scenario:
| Scenario | What happens |
|---|---|
(1) The producer is created using the given schema. (2) Since no existing schema is compatible with the SensorReading schema, the schema is transmitted to the broker and stored. (3) Any consumer created using the same schema or topic can consume messages from the sensor-data topic. | |
| (1) The schema is transmitted to the broker. (2) The broker determines that the schema is compatible. (3) The broker attempts to store the schema in BookKeeper but then determines that it's already stored, so it is used to tag produced messages. |
How does schema work
Pulsar schemas are applied and enforced at the topic level (schemas cannot be applied at the namespace or tenant level).
Producers and consumers upload schemas to brokers, so Pulsar schemas work on the producer side and the consumer side.
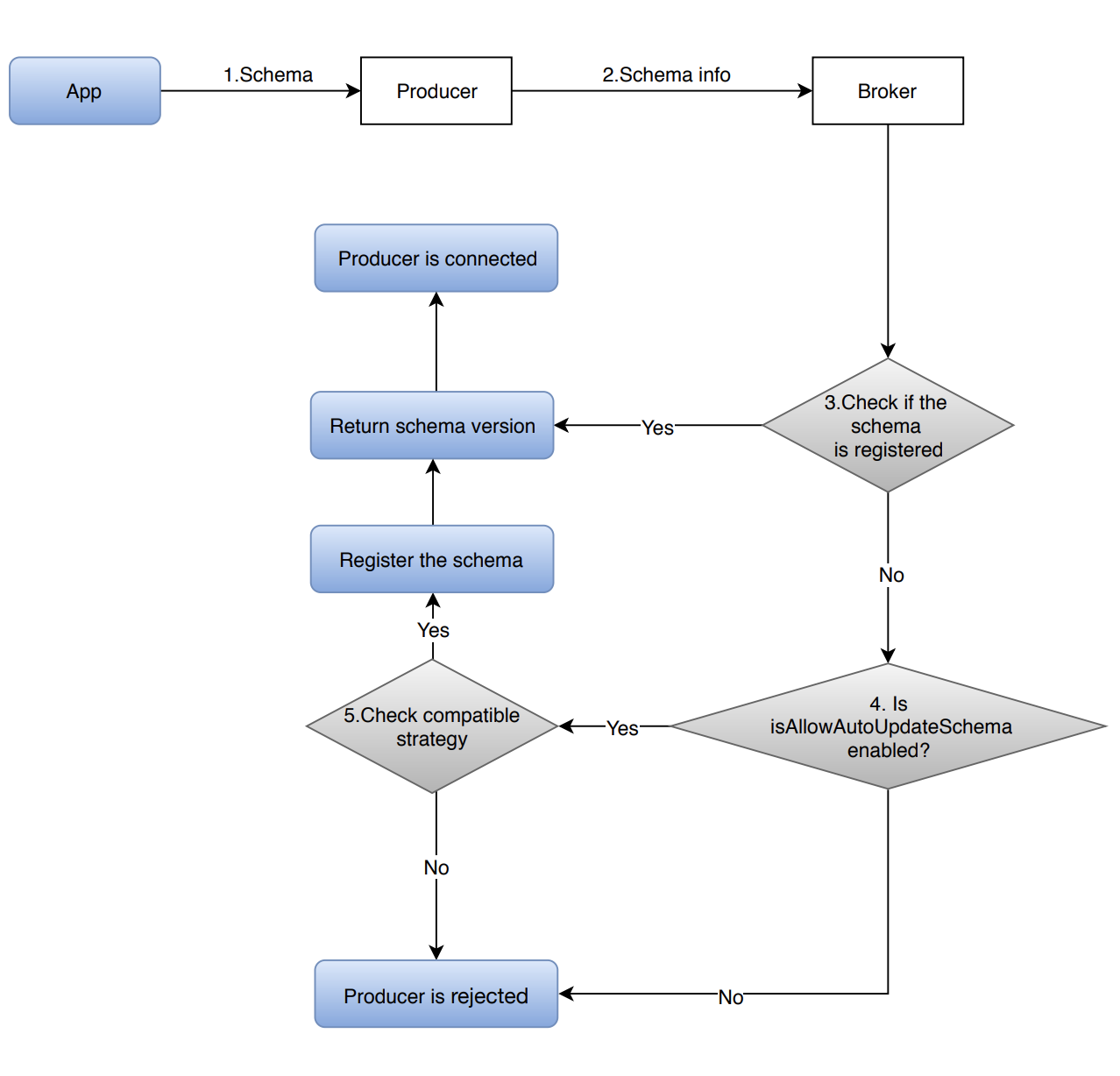
Producer side
This diagram illustrates how does schema work on the Producer side.
-
The application uses a schema instance to construct a producer instance.
The schema instance defines the schema for the data being produced using the producer instance.
Take AVRO as an example, Pulsar extracts schema definition from the POJO class and constructs the
SchemaInfothat the producer needs to pass to a broker when it connects. -
The producer connects to the broker with the
SchemaInfoextracted from the passed-in schema instance. -
The broker looks up the schema in the schema storage to check if it is already a registered schema.
-
If yes, the broker skips the schema validation since it is a known schema, and returns the schema version to the producer.
-
If no, the broker verifies whether a schema can be automatically created in this namespace:
-
If
isAllowAutoUpdateSchemasets to true, then a schema can be created, and the broker validates the schema based on the schema compatibility check strategy defined for the topic. -
If
isAllowAutoUpdateSchemasets to false, then a schema can not be created, and the producer is rejected to connect to the broker.
Tip:
isAllowAutoUpdateSchema can be set via Pulsar admin API or REST API.
For how to set isAllowAutoUpdateSchema via Pulsar admin API, see Manage AutoUpdate Strategy.
- If the schema is allowed to be updated, then the compatible strategy check is performed.
- If the schema is compatible, the broker stores it and returns the schema version to the producer.
All the messages produced by this producer are tagged with the schema version.
- If the schema is incompatible, the broker rejects it.
Consumer side
This diagram illustrates how does Schema work on the consumer side.
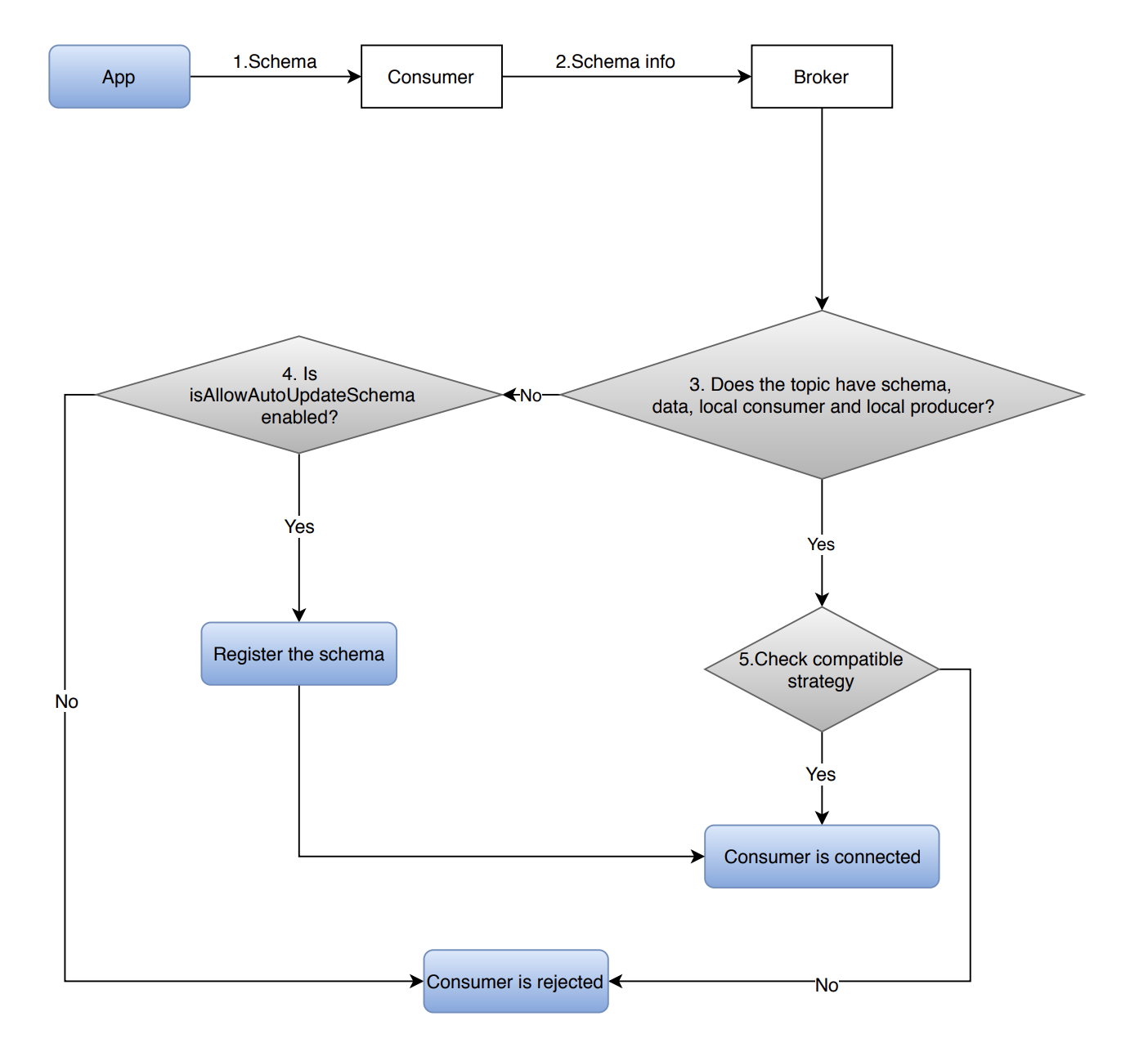
-
The application uses a schema instance to construct a consumer instance.
The schema instance defines the schema that the consumer uses for decoding messages received from a broker.
-
The consumer connects to the broker with the
SchemaInfoextracted from the passed-in schema instance. -
The broker determines whether the topic has one of them (a schema/data/a local consumer and a local producer).
-
If a topic does not have all of them (a schema/data/a local consumer and a local producer):
-
If
isAllowAutoUpdateSchemasets to true, then the consumer registers a schema and it is connected to a broker. -
If
isAllowAutoUpdateSchemasets to false, then the consumer is rejected to connect to a broker.
-
-
If a topic has one of them (a schema/data/a local consumer and a local producer), then the schema compatibility check is performed.
-
If the schema passes the compatibility check, then the consumer is connected to the broker.
-
If the schema does not pass the compatibility check, then the consumer is rejected to connect to the broker.
-
-
The consumer receives messages from the broker.
If the schema used by the consumer supports schema versioning (for example, AVRO schema), the consumer fetches the
SchemaInfoof the version tagged in messages and uses the passed-in schema and the schema tagged in messages to decode the messages.