Pulsar Functions overview
This section introduces the following content:
What are Pulsar Functions
Pulsar Functions are a serverless computing framework that runs on top of Pulsar and processes messages in the following way:
- consumes messages from one or more topics,
- applies a user-defined processing logic to the messages,
- publishes the outputs of the messages to other topics.
The diagram below illustrates the three steps in the functions computing process.

Each time a function receives a message, it completes the following consume-apply-publish steps.
- Consumes the message from one or more input topics.
- Applies the customized (user-supplied) processing logic to the message.
- Publishes the output of the message, including:
- writes output messages to an output topic in Pulsar
- writes logs to a log topic (if it is configured)for debugging
- writes state updates to BookKeeper (if it is configured)
You can write functions in Java, Python, and Go. For example, you can use Pulsar Functions to set up the following processing chain:
- A Python function listens for the
raw-sentencestopic and "sanitizes" incoming strings (removing extraneous white space and converting all characters to lowercase) and then publishes the results to asanitized-sentencestopic. - A Java function listens for the
sanitized-sentencestopic, counts the number of times each word appears within a specified time window, and publishes the results to aresultstopic. - A Python function listens for the
resultstopic and writes the results to a MySQL table.
See Develop Pulsar Functions for more details.
Why use Pulsar Functions
Pulsar Functions perform simple computations on messages before routing the messages to consumers. These Lambda-style functions are specifically designed and integrated with Pulsar. The framework provides a simple computing framework on your Pulsar cluster and takes care of the underlying details of sending and receiving messages. You only need to focus on the business logic.
Pulsar Functions enable your organization to maximize the value of your data and enjoy the benefits of:
- Simplified deployment and operations - you can create a data pipeline without deploying a separate Stream Processing Engine (SPE), such as Apache Storm, Apache Heron, or Apache Flink.
- Serverless computing (when you use Kubernetes runtime)
- Maximized developer productivity (both language-native interfaces and SDKs for Java/Python/Go).
- Easy troubleshooting
Use cases
Below are two simple examples of use cases for Pulsar Functions.
Word count example
This figure shows the process of implementing the classic word count use case.
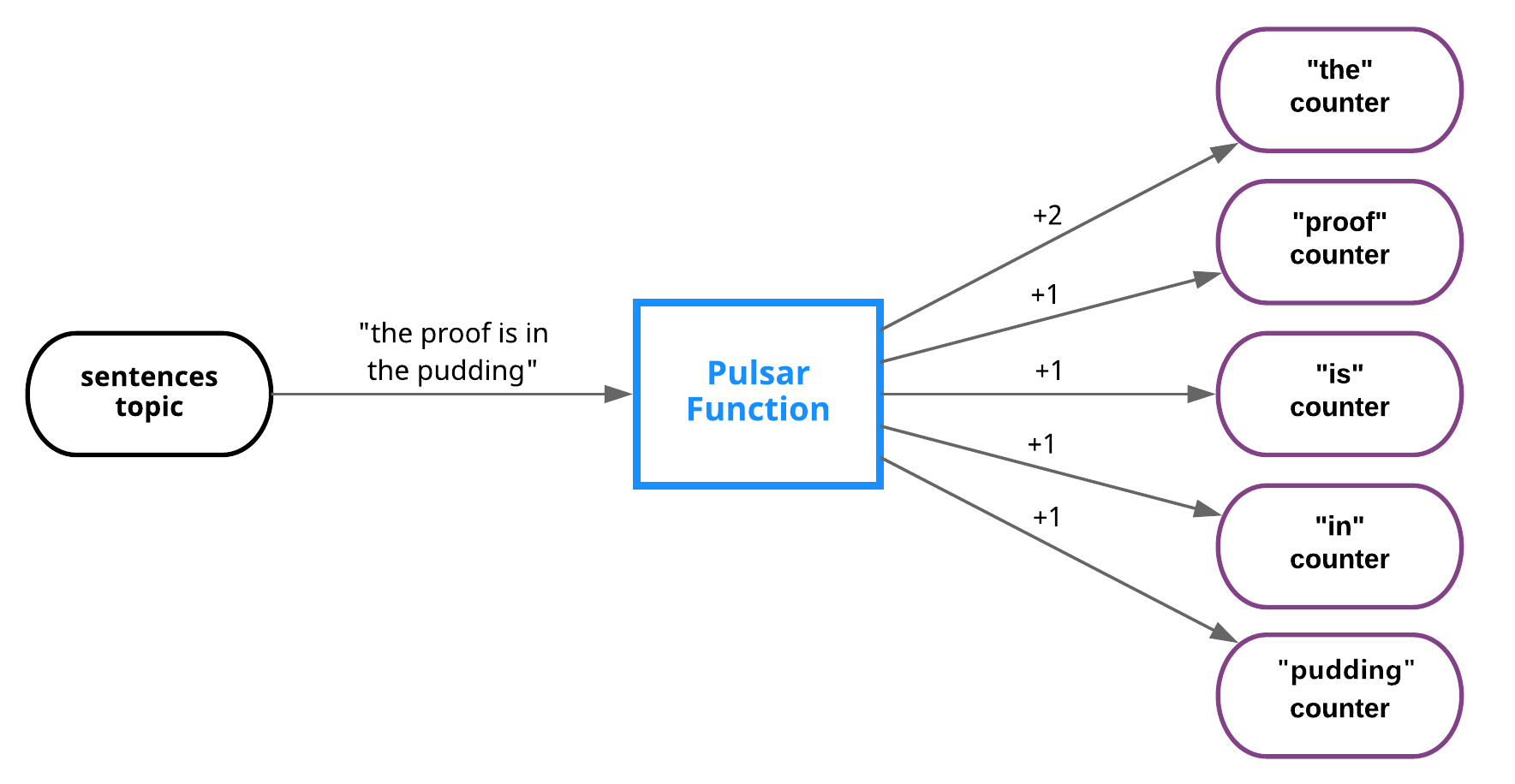
In this example, the function calculates a sum of the occurrences of every individual word published to a given topic.
Content-based routing example
This figure demonstrates the process of implementing a content-based routing use case.
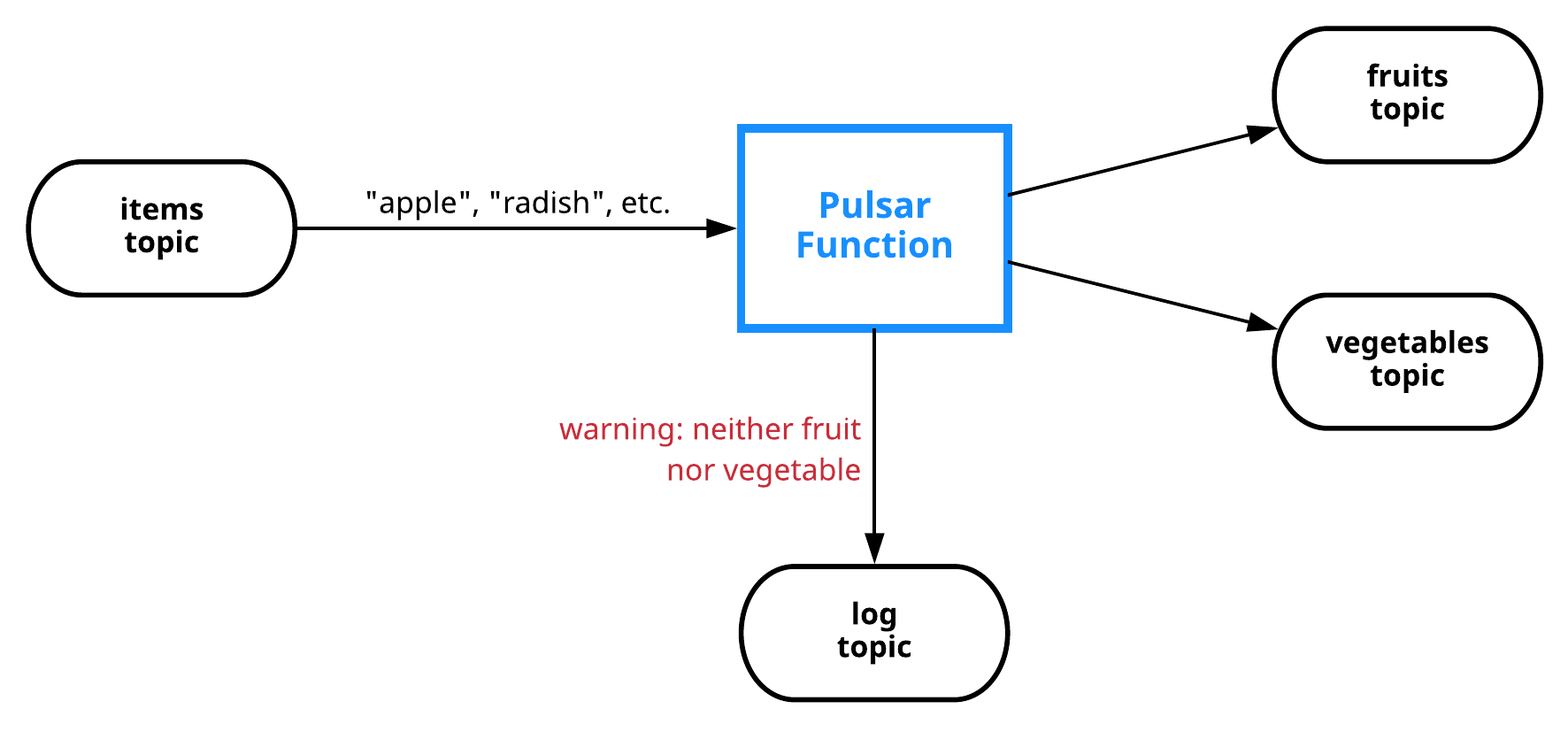
In this example, a function takes items (strings) as input and publishes them to either a fruits or vegetables topic, depending on the item. If an item is neither fruit nor vegetable, a warning is logged to a log topic.
What's next?
For developers
For admins/operators