Architecture Overview
At the highest level, a Pulsar instance is composed of one or more Pulsar clusters. Clusters within an instance can replicate data amongst themselves.
A Pulsar cluster consists of the following components:
- One or more brokers handles and load balances incoming messages from producers, dispatches messages to consumers, communicates with the Pulsar metadata store to handle various coordination tasks, stores messages in BookKeeper instances (aka bookies), and coordinates cluster operations through the metadata store.
- A BookKeeper cluster consisting of one or more bookies handles persistent storage of messages.
- A metadata store cluster (ZooKeeper, etcd, or other supported backend) handles coordination tasks and cluster-specific metadata storage.
The diagram below illustrates a Pulsar cluster:
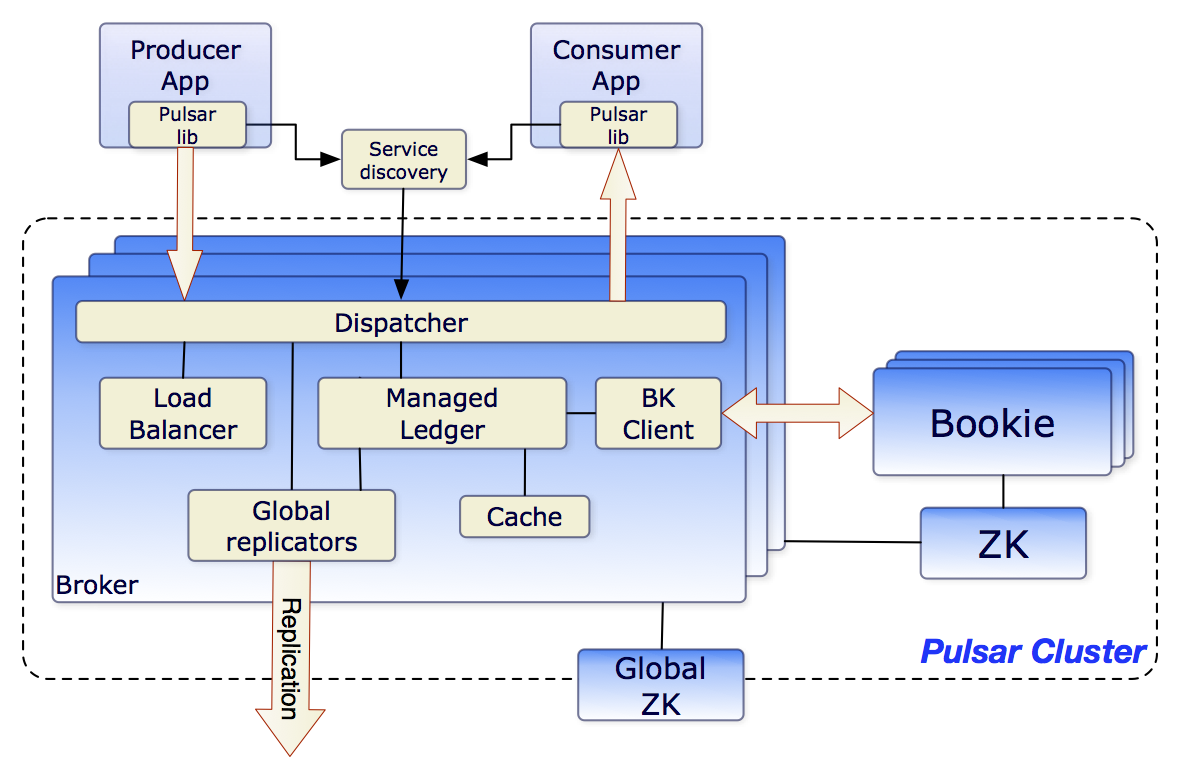
At the broader instance level, an instance-wide ZooKeeper cluster called the configuration store handles coordination tasks involving multiple clusters, for example, geo-replication.
Brokers
The Pulsar message broker is a stateless component that's primarily responsible for running two other components:
- An HTTP server that exposes a REST API for both administrative tasks and topic lookup for producers and consumers. The producers connect to the brokers to publish messages and the consumers connect to the brokers to consume the messages.
- A dispatcher, which is an asynchronous TCP server over a custom binary protocol used for all data transfers
Messages are typically dispatched out of a managed ledger cache for the sake of performance, unless the backlog exceeds the cache size. If the backlog grows too large for the cache, the broker will start reading entries from BookKeeper.
Finally, to support geo-replication on global topics, the broker manages replicators that tail the entries published in the local region and republish them to the remote region using the Pulsar Java client library.
For a guide to managing Pulsar brokers, see the brokers guide.
Clusters
A Pulsar instance consists of one or more Pulsar clusters. Clusters, in turn, consist of:
- One or more Pulsar brokers
- A ZooKeeper quorum used for cluster-level configuration and coordination
- An ensemble of bookies used for persistent storage of messages
Clusters can replicate among themselves using geo-replication.
For a guide to managing Pulsar clusters, see the clusters guide.
Metadata store
The Pulsar metadata store maintains all the metadata of a Pulsar cluster, such as topic metadata, schema, broker load data, and so on. Pulsar supports multiple metadata store backends to provide flexibility in deployment architectures and operational requirements:
Supported Metadata Store Backends
- Apache ZooKeeper - Default option, production-ready metadata store with strong consistency guarantees.
- etcd - Cloud-native distributed key-value store, ideal for Kubernetes environments and cloud deployments.
- RocksDB - Embedded key-value store for standalone Pulsar deployments, eliminating the need for external coordination services.
- Oxia - A robust, scalable metadata store and coordination system designed for large-scale distributed systems, with built-in support for stream index storage to optimize real-time data management.
Configuration
You can configure the metadata store using the metadataStoreUrl parameter:
# ZooKeeper
metadataStoreUrl=zk:my-zk-1:2181,my-zk-2:2181,my-zk-3:2181
# etcd
metadataStoreUrl=etcd:my-etcd-1:2379,my-etcd-2:2379,my-etcd-3:2379
# RocksDB (standalone)
metadataStoreUrl=rocksdb:///path/to/data
# Oxia
metadataStoreUrl=oxia:oxia-server:6648
Deployment Considerations
The Pulsar metadata store can be deployed on a separate cluster or integrated with existing infrastructure. You can use one ZooKeeper cluster for both Pulsar metadata store and BookKeeper metadata store. If you want to deploy Pulsar brokers connected to an existing BookKeeper cluster, you need to deploy separate clusters for Pulsar metadata store and BookKeeper metadata store respectively.
In a Pulsar instance:
- A configuration store quorum stores configuration for tenants, namespaces, and other entities that need to be globally consistent.
- Each cluster has its own local ZooKeeper ensemble that stores cluster-specific configuration and coordination such as which brokers are responsible for which topics as well as ownership metadata, broker load reports, BookKeeper ledger metadata, and more.
Configuration store
The configuration store is a ZooKeeper quorum that is used for configuration-specific tasks and it maintains all the configurations of a Pulsar instance, such as clusters, tenants, namespaces, partitioned topic-related configurations, and so on. A Pulsar instance can have a single local cluster, multiple local clusters, or multiple cross-region clusters. Consequently, the configuration store can share the configurations across multiple clusters under a Pulsar instance. The configuration store can be deployed on a separate ZooKeeper cluster or deployed on an existing ZooKeeper cluster.
Persistent storage
Pulsar provides guaranteed message delivery for applications. If a message successfully reaches a Pulsar broker, it will be delivered to its intended target.
This guarantee requires that non-acknowledged messages are stored durably until they can be delivered to and acknowledged by consumers. This mode of messaging is commonly called persistent messaging. In Pulsar, N copies of all messages are stored and synced on disk, for example, 4 copies across two servers with mirrored RAID volumes on each server.
Apache BookKeeper
Pulsar uses a system called Apache BookKeeper for persistent message storage. BookKeeper is a distributed write-ahead log (WAL) system that provides several crucial advantages for Pulsar:
- It enables Pulsar to utilize many independent logs, called ledgers. Multiple ledgers can be created for topics over time.
- It offers very efficient storage for sequential data that handles entry replication.
- It guarantees read consistency of ledgers in the presence of various system failures.
- It offers even distribution of I/O across bookies.
- It's horizontally scalable in both capacity and throughput. Capacity can be immediately increased by adding more bookies to a cluster.
- Bookies are designed to handle thousands of ledgers with concurrent reads and writes. By using multiple disk devices---one for journal and another for general storage--bookies can isolate the effects of reading operations from the latency of ongoing write operations.
In addition to message data, cursors are also persistently stored in BookKeeper. Cursors are subscription positions for consumers. BookKeeper enables Pulsar to store consumer position in a scalable fashion.
At the moment, Pulsar supports persistent message storage. This accounts for the persistent in all topic names. Here's an example:
persistent://my-tenant/my-namespace/my-topic
Pulsar also supports ephemeral non-persistent message storage.
You can see an illustration of how brokers and bookies interact in the diagram below:
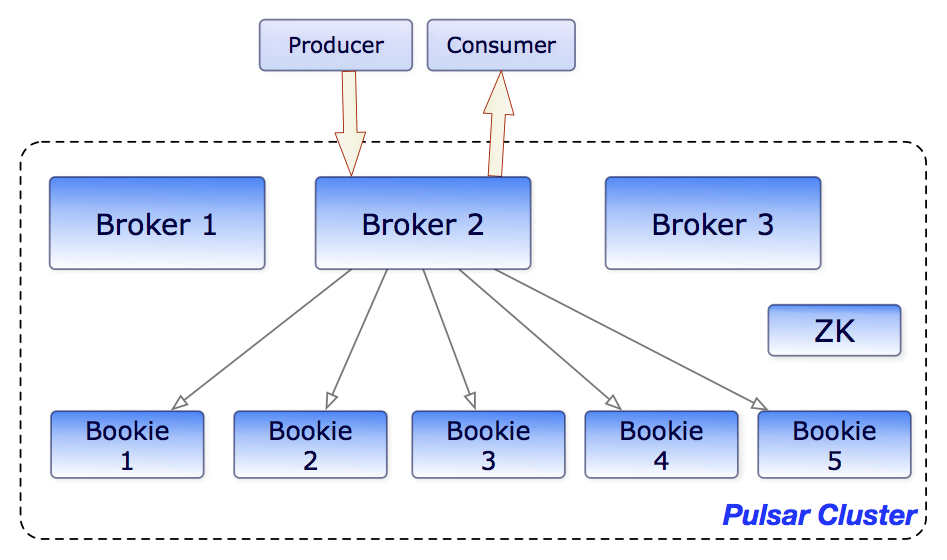
Ledgers
A ledger is an append-only data structure with a single writer that is assigned to multiple BookKeeper storage nodes, or bookies. Ledger entries are replicated to multiple bookies. Ledgers themselves have very simple semantics:
- A Pulsar broker can create a ledger, append entries to the ledger, and close the ledger.
- After the ledger has been closed---either explicitly or because the writer process crashed---it can then be opened only in read-only mode.
- Finally, when entries in the ledger are no longer needed, the whole ledger can be deleted from the system (across all bookies).
Ledger read consistency
The main strength of Bookkeeper is that it guarantees read consistency in ledgers in the presence of failures. Since the ledger can only be written to by a single process, that process is free to append entries very efficiently, without need to obtain consensus. After a failure, the ledger will go through a recovery process that will finalize the state of the ledger and establish which entry was last committed to the log. After that point, all readers of the ledger are guaranteed to see the exact same content.
Managed ledgers
Given that Bookkeeper ledgers provide a single log abstraction, a library was developed on top of the ledger called the managed ledger that represents the storage layer for a single topic. A managed ledger represents the abstraction of a stream of messages with a single writer that keeps appending at the end of the stream and multiple cursors that are consuming the stream, each with its own associated position.
Internally, a single managed ledger uses multiple BookKeeper ledgers to store the data. There are two reasons to have multiple ledgers:
- After a failure, a ledger is no longer writable and a new one needs to be created.
- A ledger can be deleted when all cursors have consumed the messages it contains. This allows for periodic rollover of ledgers.
Journal storage
In BookKeeper, journal files contain BookKeeper transaction logs. Before making an update to a ledger, a bookie needs to ensure that a transaction describing the update is written to persistent (non-volatile) storage. A new journal file is created once the bookie starts or the older journal file reaches the journal file size threshold (configured using the journalMaxSizeMB parameter).
Pulsar proxy
One way for Pulsar clients to interact with a Pulsar cluster is by connecting to Pulsar message brokers directly. In some cases, however, this kind of direct connection is either infeasible or undesirable because the client doesn't have direct access to broker addresses. If you're running Pulsar in a cloud environment or on Kubernetes or an analogous platform, for example, then direct client connections to brokers are likely not possible.
The Pulsar proxy provides a solution to this problem by acting as a single gateway for all of the brokers in a cluster. If you run the Pulsar proxy (which, again, is optional), all client connections with the Pulsar cluster will flow through the proxy rather than communicating with brokers.
For the sake of performance and fault tolerance, you can run as many instances of the Pulsar proxy as you'd like.
Architecturally, the Pulsar proxy gets all the information it requires from the metadata store. When starting the proxy on a machine, you only need to provide metadata store connection strings for the cluster-specific and instance-wide configuration store clusters. Here's an example:
cd /path/to/pulsar/directory
# Using ZooKeeper
bin/pulsar proxy \
--metadata-store zk:my-zk-1:2181,my-zk-2:2181,my-zk-3:2181 \
--configuration-metadata-store zk:my-zk-1:2181,my-zk-2:2181,my-zk-3:2181
# Using etcd
bin/pulsar proxy \
--metadata-store etcd:my-etcd-1:2379,my-etcd-2:2379 \
--configuration-metadata-store etcd:my-etcd-1:2379,my-etcd-2:2379
Pulsar proxy docs
For documentation on using the Pulsar proxy, see the Pulsar proxy admin documentation.
Some important things to know about the Pulsar proxy:
- Connecting clients don't need to provide any specific configuration to use the Pulsar proxy. You won't need to update the client configuration for existing applications beyond updating the IP used for the service URL (for example if you're running a load balancer over the Pulsar proxy).
- TLS encryption and mTLS authentication is supported by the Pulsar proxy
Service discovery
Service discovery is a mechanism that enables connecting clients to use just a single URL to interact with an entire Pulsar instance.
You can use your own service discovery system if you'd like. If you use your own system, there is just one requirement: when a client performs an HTTP request to an endpoint, such as http://pulsar.us-west.example.com:8080, the client needs to be redirected to some active broker in the desired cluster, whether via DNS, an HTTP or IP redirect, or some other means.
The diagram below illustrates Pulsar service discovery:
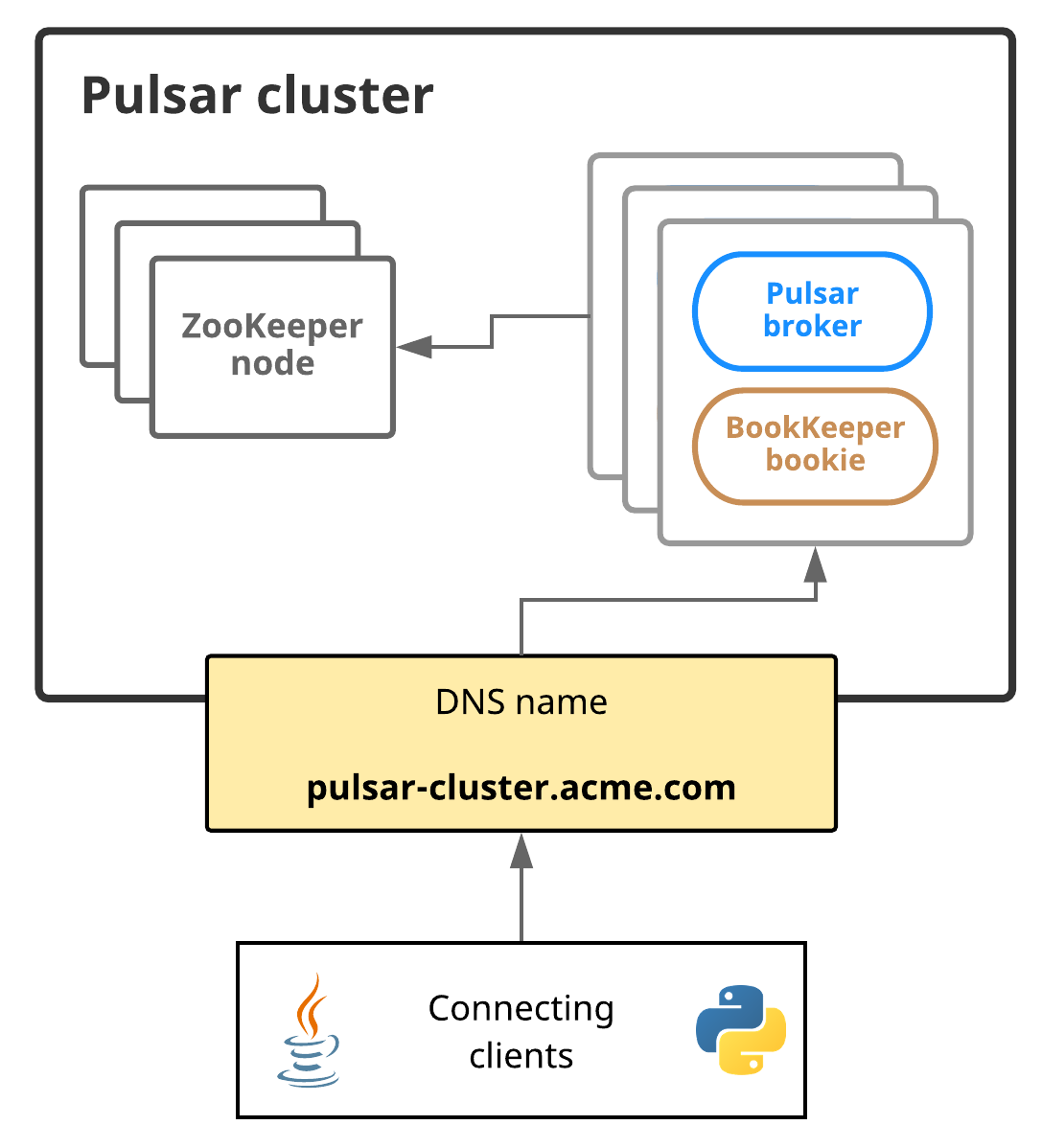
In this diagram, the Pulsar cluster is addressable via a single DNS name: pulsar-cluster.acme.com. A Python client, for example, could access this Pulsar cluster like this:
from pulsar import Client
client = Client('pulsar://pulsar-cluster.acme.com:6650')