Pulsar Java client
You can use a Pulsar Java client to create the Java producer, consumer, readers and TableView of messages and to perform administrative tasks. The current Java client version is 2.10.6.
All the methods in producer, consumer, readers and TableView of a Java client are thread-safe.
Javadoc for the Pulsar client is divided into two domains by package as follows.
| Package | Description | Maven Artifact |
|---|---|---|
org.apache.pulsar.client.api | The producer and consumer API | org.apache.pulsar:pulsar-client:2.10.6 |
org.apache.pulsar.client.admin | The Java admin API | org.apache.pulsar:pulsar-client-admin:2.10.6 |
org.apache.pulsar.client.all | Include both pulsar-client and pulsar-client-adminBoth pulsar-client and pulsar-client-admin are shaded packages and they shade dependencies independently. Consequently, the applications using both pulsar-client and pulsar-client-admin have redundant shaded classes. It would be troublesome if you introduce new dependencies but forget to update shading rules. In this case, you can use pulsar-client-all, which shades dependencies only one time and reduces the size of dependencies. | org.apache.pulsar:pulsar-client-all:2.10.6 |
This document focuses only on the client API for producing and consuming messages on Pulsar topics. For how to use the Java admin client, see Pulsar admin interface.
Installation
The latest version of the Pulsar Java client library is available via Maven Central. To use the latest version, add the pulsar-client library to your build configuration.
pulsar-clientandpulsar-client-adminshade dependencies via maven-shade-plugin to avoid conflicts of the underlying dependency packages (such as Netty). If you do not want to manage dependency conflicts manually, you can use them.pulsar-client-originalandpulsar-client-admin-originaldoes not shade dependencies. If you want to manage dependencies manually, you can use them.
Maven
If you use Maven, add the following information to the pom.xml file.
<!-- in your <properties> block -->
<pulsar.version>2.10.6</pulsar.version>
<!-- in your <dependencies> block -->
<dependency>
<groupId>org.apache.pulsar</groupId>
<artifactId>pulsar-client</artifactId>
<version>${pulsar.version}</version>
</dependency>
Gradle
If you use Gradle, add the following information to the build.gradle file.
def pulsarVersion = '2.10.6'
dependencies {
compile group: 'org.apache.pulsar', name: 'pulsar-client', version: pulsarVersion
}
Connection URLs
To connect to Pulsar using client libraries, you need to specify a Pulsar protocol URL.
You can assign Pulsar protocol URLs to specific clusters and use the pulsar scheme. The default port is 6650. The following is an example of localhost.
pulsar://localhost:6650
If you have multiple brokers, the URL is as follows.
pulsar://localhost:6550,localhost:6651,localhost:6652
A URL for a production Pulsar cluster is as follows.
pulsar://pulsar.us-west.example.com:6650
If you use TLS authentication, the URL is as follows.
pulsar+ssl://pulsar.us-west.example.com:6651
Client
You can instantiate a PulsarClient object using just a URL for the target Pulsar cluster like this:
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650")
.build();
If you have multiple brokers, you can initiate a PulsarClient like this:
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://localhost:6650,localhost:6651,localhost:6652")
.build();
Default broker URLs for standalone clusters
If you run a cluster in standalone mode, the broker is available at the
pulsar://localhost:6650URL by default.
If you create a client, you can use the loadConf configuration. The following parameters are available in loadConf.
| Name | Type | Description | Default |
|---|---|---|---|
serviceUrl | String | Service URL provider for Pulsar service | None |
authPluginClassName | String | Name of the authentication plugin | None |
authParams | String | Parameters for the authentication plugin Example key1:val1,key2:val2 | None |
operationTimeoutMs | long | operationTimeoutMs | Operation timeout |
statsIntervalSeconds | long | Interval between each stats information Stats is activated with positive statsIntervalSet statsIntervalSeconds to 1 second at least. | 60 |
numIoThreads | int | The number of threads used for handling connections to brokers | 1 |
numListenerThreads | int | The number of threads used for handling message listeners. The listener thread pool is shared across all the consumers and readers using the "listener" model to get messages. For a given consumer, the listener is always invoked from the same thread to ensure ordering. If you want multiple threads to process a single topic, you need to create a shared subscription and multiple consumers for this subscription. This does not ensure ordering. | 1 |
useTcpNoDelay | boolean | Whether to use TCP no-delay flag on the connection to disable Nagle algorithm | true |
enableTls | boolean | Whether to use TLS encryption on the connection. Note that this parameter is deprecated. If you want to enable TLS, use pulsar+ssl:// in serviceUrl instead. | false |
tlsTrustCertsFilePath | string | Path to the trusted TLS certificate file | None |
tlsAllowInsecureConnection | boolean | Whether the Pulsar client accepts untrusted TLS certificate from broker | false |
tlsHostnameVerificationEnable | boolean | Whether to enable TLS hostname verification | false |
concurrentLookupRequest | int | The number of concurrent lookup requests allowed to send on each broker connection to prevent overload on broker | 5000 |
maxLookupRequest | int | The maximum number of lookup requests allowed on each broker connection to prevent overload on broker | 50000 |
maxNumberOfRejectedRequestPerConnection | int | The maximum number of rejected requests of a broker in a certain time frame (60 seconds) after the current connection is closed and the client creates a new connection to connect to a different broker | 50 |
keepAliveIntervalSeconds | int | Seconds of keeping alive interval for each client broker connection | 30 |
connectionTimeoutMs | int | Duration of waiting for a connection to a broker to be established If the duration passes without a response from a broker, the connection attempt is dropped | 10000 |
requestTimeoutMs | int | Maximum duration for completing a request | 60000 |
defaultBackoffIntervalNanos | int | Default duration for a backoff interval | TimeUnit.MILLISECONDS.toNanos(100); |
maxBackoffIntervalNanos | long | Maximum duration for a backoff interval | TimeUnit.SECONDS.toNanos(30) |
socks5ProxyAddress | SocketAddress | SOCKS5 proxy address | None |
socks5ProxyUsername | string | SOCKS5 proxy username | None |
socks5ProxyPassword | string | SOCKS5 proxy password | None |
Check out the Javadoc for the PulsarClient class for a full list of configurable parameters.
In addition to client-level configuration, you can also apply producer and consumer specific configuration as described in sections below.
Client memory allocator configuration
You can set the client memory allocator configurations through Java properties.
| Property | Type | Description | Default | Available values |
|---|---|---|---|---|
pulsar.allocator.pooled | String | If set to true, the client uses a direct memory pool. If set to false, the client uses a heap memory without pool | true | |
pulsar.allocator.exit_on_oom | String | Whether to exit the JVM when OOM happens | false | |
pulsar.allocator.leak_detection | String | The leak detection policy for Pulsar bytebuf allocator. | Disabled | |
pulsar.allocator.out_of_memory_policy | String | When an OOM occurs, the client throws an exception or fallbacks to heap | FallbackToHeap |
Example:
-Dpulsar.allocator.pooled=true
-Dpulsar.allocator.exit_on_oom=false
-Dpulsar.allocator.leak_detection=Disabled
-Dpulsar.allocator.out_of_memory_policy=ThrowException
Cluster-level failover
This chapter describes the concept, benefits, use cases, constraints, usage, working principles, and more information about the cluster-level failover. It contains the following sections:
What is cluster-level failover
This chapter helps you better understand the concept of cluster-level failover.
Concept of cluster-level failover
- Automatic cluster-level failover
- Controlled cluster-level failover
Automatic cluster-level failover supports Pulsar clients switching from a primary cluster to one or several backup clusters automatically and seamlessly when it detects a failover event based on the configured detecting policy set by users.
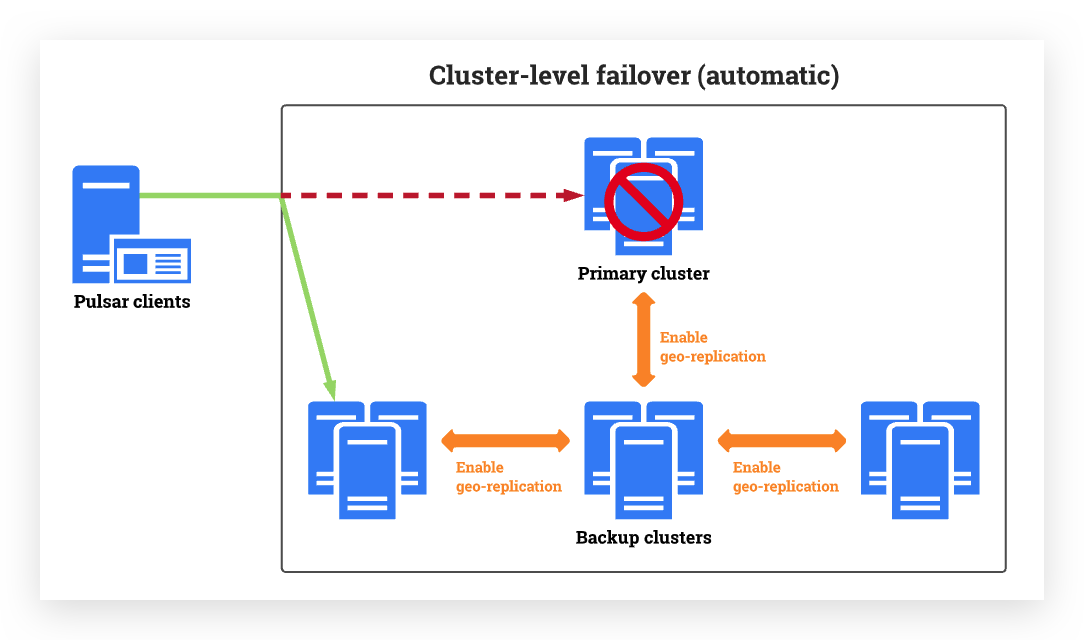
Controlled cluster-level failover supports Pulsar clients switching from a primary cluster to one or several backup clusters. The switchover is manually set by administrators.
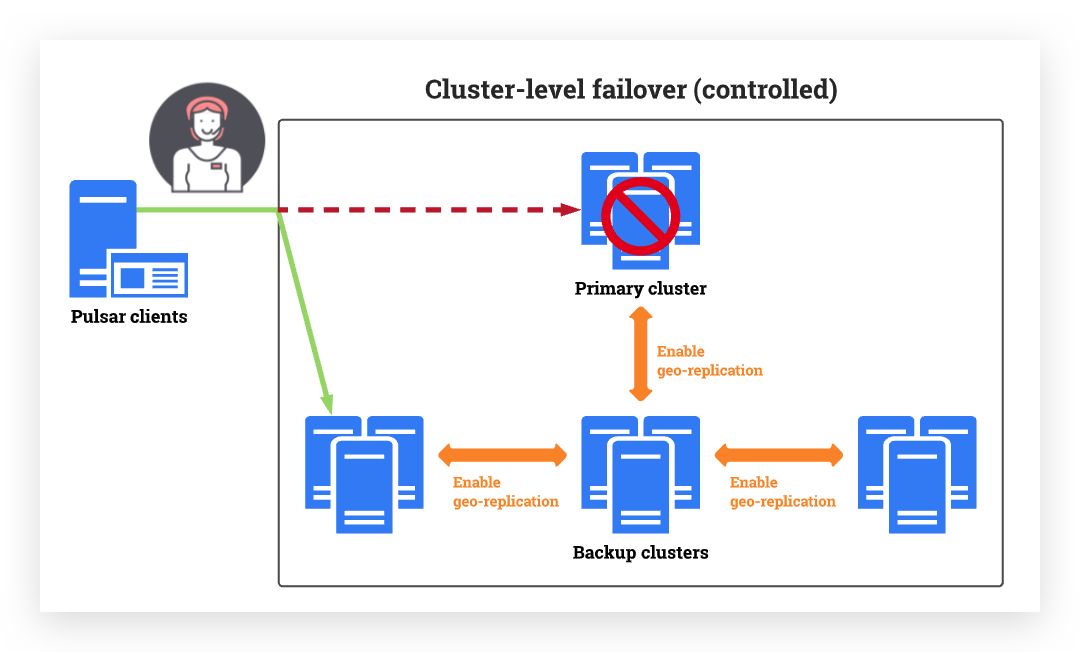
Once the primary cluster functions again, Pulsar clients can switch back to the primary cluster. Most of the time users won’t even notice a thing. Users can keep using applications and services without interruptions or timeouts.
Why use cluster-level failover?
The cluster-level failover provides fault tolerance, continuous availability, and high availability together. It brings a number of benefits, including but not limited to:
-
Reduced cost: services can be switched and recovered automatically with no data loss.
-
Simplified management: businesses can operate on an "always-on" basis since no immediate user intervention is required.
-
Improved stability and robustness: it ensures continuous performance and minimizes service downtime.
When to use cluster-level failover?
The cluster-level failover protects your environment in a number of ways, including but not limited to:
-
Disaster recovery: cluster-level failover can automatically and seamlessly transfer the production workload on a primary cluster to one or several backup clusters, which ensures minimum data loss and reduced recovery time.
-
Planned migration: if you want to migrate production workloads from an old cluster to a new cluster, you can improve the migration efficiency with cluster-level failover. For example, you can test whether the data migration goes smoothly in case of a failover event, identify possible issues and risks before the migration.
When cluster-level failover is triggered?
- Automatic cluster-level failover
- Controlled cluster-level failover
Automatic cluster-level failover is triggered when Pulsar clients cannot connect to the primary cluster for a prolonged period of time. This can be caused by any number of reasons including, but not limited to:
-
Network failure: internet connection is lost.
-
Power failure: shutdown time of a primary cluster exceeds time limits.
-
Service error: errors occur on a primary cluster (for example, the primary cluster does not function because of time limits).
-
Crashed storage space: the primary cluster does not have enough storage space, but the corresponding storage space on the backup server functions normally.
Controlled cluster-level failover is triggered when administrators set the switchover manually.
Why does cluster-level failover fail?
Obviously, the cluster-level failover does not succeed if the backup cluster is unreachable by active Pulsar clients. This can happen for many reasons, including but not limited to:
-
Power failure: the backup cluster is shut down or does not function normally.
-
Crashed storage space: primary and backup clusters do not have enough storage space.
-
If the failover is initiated, but no cluster can assume the role of an available cluster due to errors, and the primary cluster is not able to provide service normally.
-
If you manually initiate a switchover, but services cannot be switched to the backup cluster server, then the system will attempt to switch services back to the primary cluster.
-
Fail to authenticate or authorize between 1) primary and backup clusters, or 2) between two backup clusters.
What are the limitations of cluster-level failover?
Currently, cluster-level failover can perform probes to prevent data loss, but it can not check the status of backup clusters. If backup clusters are not healthy, you cannot produce or consume data.
What are the relationships between cluster-level failover and geo-replication?
The cluster-level failover is an extension of geo-replication to improve stability and robustness. The cluster-level failover depends on geo-replication, and they have some differences as below.
| Influence | Cluster-level failover | Geo-replication |
|---|---|---|
| Do administrators have heavy workloads? | No or maybe. - For the automatic cluster-level failover, the cluster switchover is triggered automatically based on the policies set by users. - For the controlled cluster-level failover, the switchover is triggered manually by administrators. | Yes. If a cluster fails, immediate administration intervention is required. |
| Result in data loss? | No. For both automatic and controlled cluster-level failover, if the failed primary cluster doesn't replicate messages immediately to the backup cluster, the Pulsar client can't consume the non-replicated messages. After the primary cluster is restored and the Pulsar client switches back, the non-replicated data can still be consumed by the Pulsar client. Consequently, the data is not lost. - For the automatic cluster-level failover, services can be switched and recovered automatically with no data loss. - For the controlled cluster-level failover, services can be switched and recovered manually and data loss may happen. | Yes. Pulsar clients and DNS systems have caches. When administrators switch the DNS from a primary cluster to a backup cluster, it takes some time for cache trigger timeout, which delays client recovery time and fails to produce or consume messages. |
| Result in Pulsar client failure? | No or maybe. - For automatic cluster-level failover, services can be switched and recovered automatically and the Pulsar client does not fail. - For controlled cluster-level failover, services can be switched and recovered manually, but the Pulsar client fails before administrators can take action. | Same as above. |
How to use cluster-level failover
This section guides you through every step on how to configure cluster-level failover.
Tip
-
You should configure cluster-level failover only when the cluster contains sufficient resources to handle all possible consequences. Workload intensity on the backup cluster may increase significantly.
-
Connect clusters to an uninterruptible power supply (UPS) unit to reduce the risk of unexpected power loss.
Requirements
-
Pulsar client 2.10 or later versions.
-
For backup clusters:
-
The number of BookKeeper nodes should be equal to or greater than the ensemble quorum.
-
The number of ZooKeeper nodes should be equal to or greater than 3.
-
-
Turn on geo-replication between the primary cluster and any dependent cluster (primary to backup or backup to backup) to prevent data loss.
- Automatic cluster-level failover
- Controlled cluster-level failover
This is an example of how to construct a Java Pulsar client to use automatic cluster-level failover. The switchover is triggered automatically.
private PulsarClient getAutoFailoverClient() throws PulsarClientException {
String primaryUrl = "pulsar+ssl://localhost:6651";
String secondaryUrl = "pulsar+ssl://localhost:6661";
String primaryTlsTrustCertsFilePath = "primary/path";
Authentication primaryAuthentication = AuthenticationFactory.create(
"org.apache.pulsar.client.impl.auth.AuthenticationTls",
"tlsCertFile:/path/to/primary-my-role.cert.pem,"
+ "tlsKeyFile:/path/to/primary-role.key-pk8.pem");
String secondaryTlsTrustCertsFilePath = "secondary/path";
Authentication secondaryAuthentication = AuthenticationFactory.create(
"org.apache.pulsar.client.impl.auth.AuthenticationTls",
"tlsCertFile:/path/to/secondary-my-role.cert.pem,"
+ "tlsKeyFile:/path/to/secondary-role.key-pk8.pem");
// You can put more failover cluster config in to map
Map<String, String> secondaryTlsTrustCertsFilePaths = new HashMap<>();
secondaryTlsTrustCertsFilePaths.put(secondaryUrl, secondaryTlsTrustCertsFilePath);
Map<String, Authentication> secondaryAuthentications = new HashMap<>();
secondaryAuthentications.put(secondaryUrl, secondaryAuthentication);
ServiceUrlProvider failover = AutoClusterFailover.builder()
.primary(primaryUrl)
.secondary(List.of(secondaryUrl))
.failoverDelay(30, TimeUnit.SECONDS)
.switchBackDelay(60, TimeUnit.SECONDS)
.checkInterval(1000, TimeUnit.MILLISECONDS)
.secondaryTlsTrustCertsFilePath(secondaryTlsTrustCertsFilePaths)
.secondaryAuthentication(secondaryAuthentications)
.build();
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrlProvider(failover)
.authentication(primaryAuthentication)
.tlsTrustCertsFilePath(primaryTlsTrustCertsFilePath)
.build();
failover.initialize(pulsarClient);
return pulsarClient;
}
Configure the following parameters:
| Parameter | Default value | Required? | Description |
|---|---|---|---|
primary | N/A | Yes | Service URL of the primary cluster. |
secondary | N/A | Yes | Service URL(s) of one or several backup clusters. You can specify several backup clusters using a comma-separated list. Note that: - The backup cluster is chosen in the sequence shown in the list. - If all backup clusters are available, the Pulsar client chooses the first backup cluster. |
failoverDelay | N/A | Yes | The delay before the Pulsar client switches from the primary cluster to the backup cluster. Automatic failover is controlled by a probe task: 1) The probe task first checks the health status of the primary cluster. 2) If the probe task finds the continuous failure time of the primary cluster exceeds failoverDelayMs, it switches the Pulsar client to the backup cluster. |
switchBackDelay | N/A | Yes | The delay before the Pulsar client switches from the backup cluster to the primary cluster. Automatic failover switchover is controlled by a probe task: 1) After the Pulsar client switches from the primary cluster to the backup cluster, the probe task continues to check the status of the primary cluster. 2) If the primary cluster functions well and continuously remains active longer than switchBackDelay, the Pulsar client switches back to the primary cluster. |
checkInterval | 30s | No | Frequency of performing a probe task (in seconds). |
secondaryTlsTrustCertsFilePath | N/A | No | A map of certificate file. Keys are service urls of backup cluster. Values are paths to the trusted TLS certificate file of the backup cluster. |
secondaryAuthentication | N/A | No | A map of Authentication config. Keys are service urls of backup cluster. Values are Authentication object of the backup cluster. |
This is an example of how to construct a Java Pulsar client to use controlled cluster-level failover. The switchover is triggered by administrators manually.
Note: you can have one or several backup clusters but can only specify one.
public PulsarClient getControlledFailoverClient() throws IOException {
Map<String, String> header = new HashMap();
header.put("service_user_id", "my-user");
header.put("service_password", "tiger");
header.put("clusterA", "tokenA");
header.put("clusterB", "tokenB");
ServiceUrlProvider provider = ControlledClusterFailover.builder()
.defaultServiceUrl("pulsar://localhost:6650")
.checkInterval(1, TimeUnit.MINUTES)
.urlProvider("http://localhost:8080/test")
.urlProviderHeader(header)
.build();
PulsarClient pulsarClient = PulsarClient.builder()
.serviceUrlProvider(provider)
.build();
provider.initialize(pulsarClient);
return pulsarClient;
}
| Parameter | Default value | Required? | Description |
|---|---|---|---|
defaultServiceUrl | N/A | Yes | Pulsar service URL. |
checkInterval | 30s | No | Frequency of performing a probe task (in seconds). |
urlProvider | N/A | Yes | URL provider service. |
urlProviderHeader | N/A | No | urlProviderHeader is a map containing tokens and credentials. If you enable authentication or authorization between Pulsar clients and primary and backup clusters, you need to provide urlProviderHeader. |
Here is an example of how urlProviderHeader works.
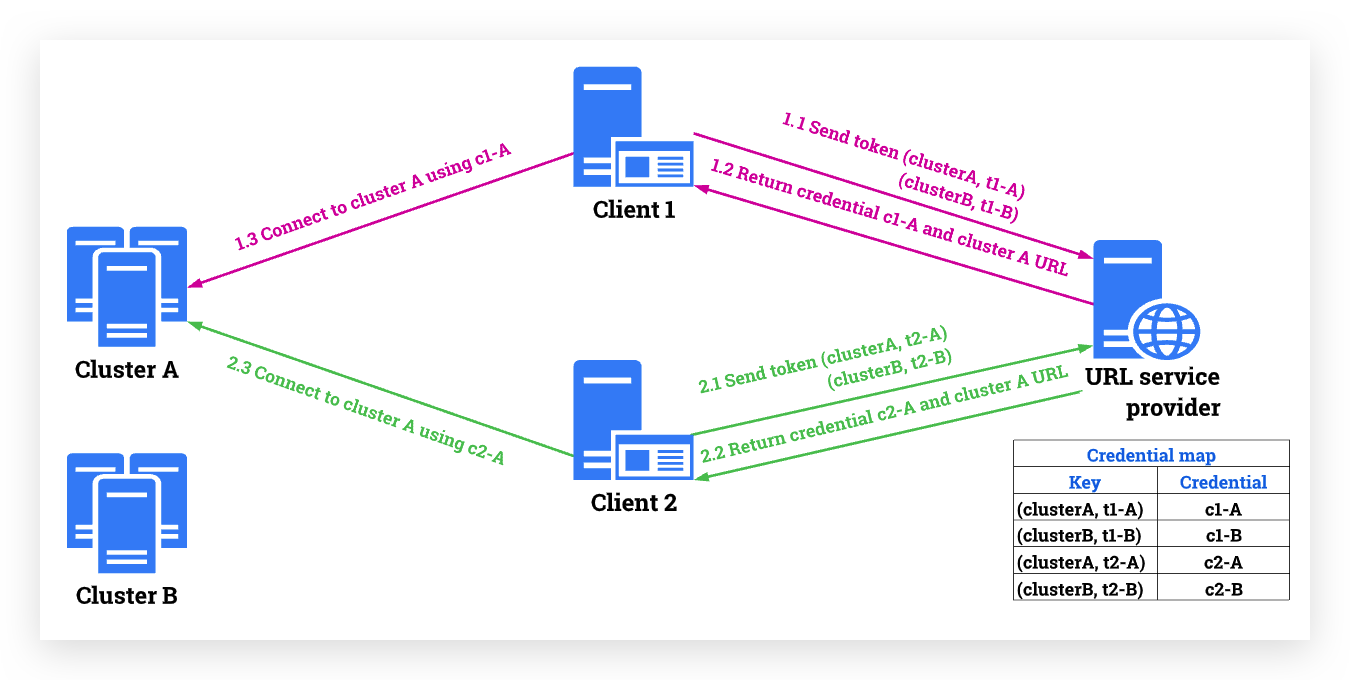
Assume that you want to connect Pulsar client 1 to cluster A.
-
Pulsar client 1 sends the token t1 to the URL provider service.
-
The URL provider service returns the credential c1 and the cluster A URL to the Pulsar client.
The URL provider service manages all tokens and credentials. It returns different credentials based on different tokens and different target cluster URLs to different Pulsar clients.
Note: the credential must be in a JSON file and contain parameters as shown.
{"serviceUrl": "pulsar+ssl://target:6651","tlsTrustCertsFilePath": "/security/ca.cert.pem","authPluginClassName":"org.apache.pulsar.client.impl.auth.AuthenticationTls","authParamsString": " \"tlsCertFile\": \"/security/client.cert.pem\"\"tlsKeyFile\": \"/security/client-pk8.pem\" "} -
Pulsar client 1 connects to cluster A using credential c1.
How does cluster-level failover work?
This chapter explains the working process of cluster-level failover. For more implementation details, see PIP-121.
- Automatic cluster-level failover
- Controlled cluster-level failover
In automatic failover cluster, the primary cluster and backup cluster are aware of each other's availability. The automatic failover cluster performs the following actions without administrator intervention:
-
The Pulsar client runs a probe task at intervals defined in
checkInterval. -
If the probe task finds the failure time of the primary cluster exceeds the time set in the
failoverDelayparameter, it searches backup clusters for an available healthy cluster.2a) If there are healthy backup clusters, the Pulsar client switches to a backup cluster in the order defined in
secondary.2b) If there is no healthy backup cluster, the Pulsar client does not perform the switchover, and the probe task continues to look for an available backup cluster.
-
The probe task checks whether the primary cluster functions well or not.
3a) If the primary cluster comes back and the continuous healthy time exceeds the time set in
switchBackDelay, the Pulsar client switches back to the primary cluster.3b) If the primary cluster does not come back, the Pulsar client does not perform the switchover.
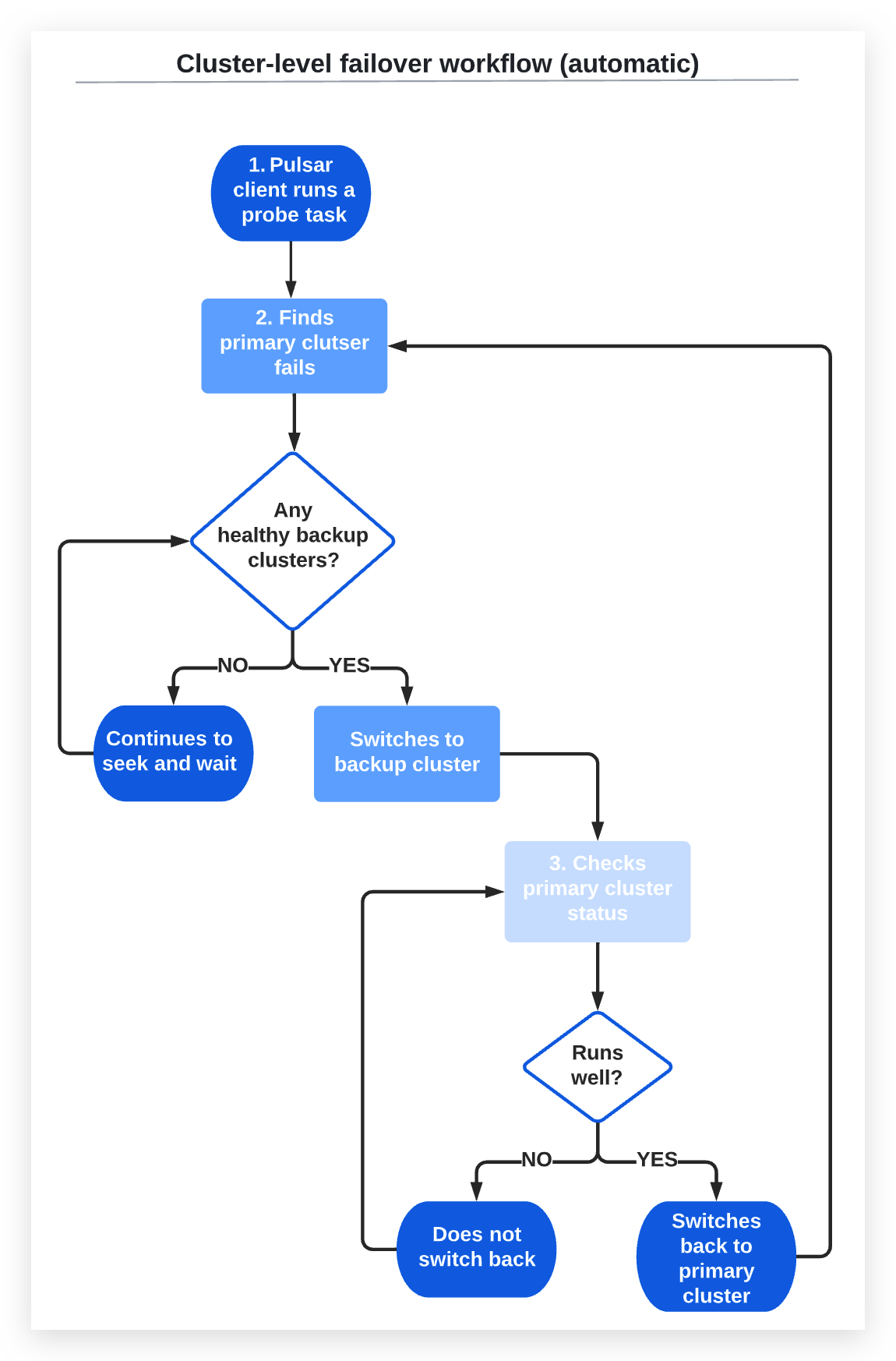
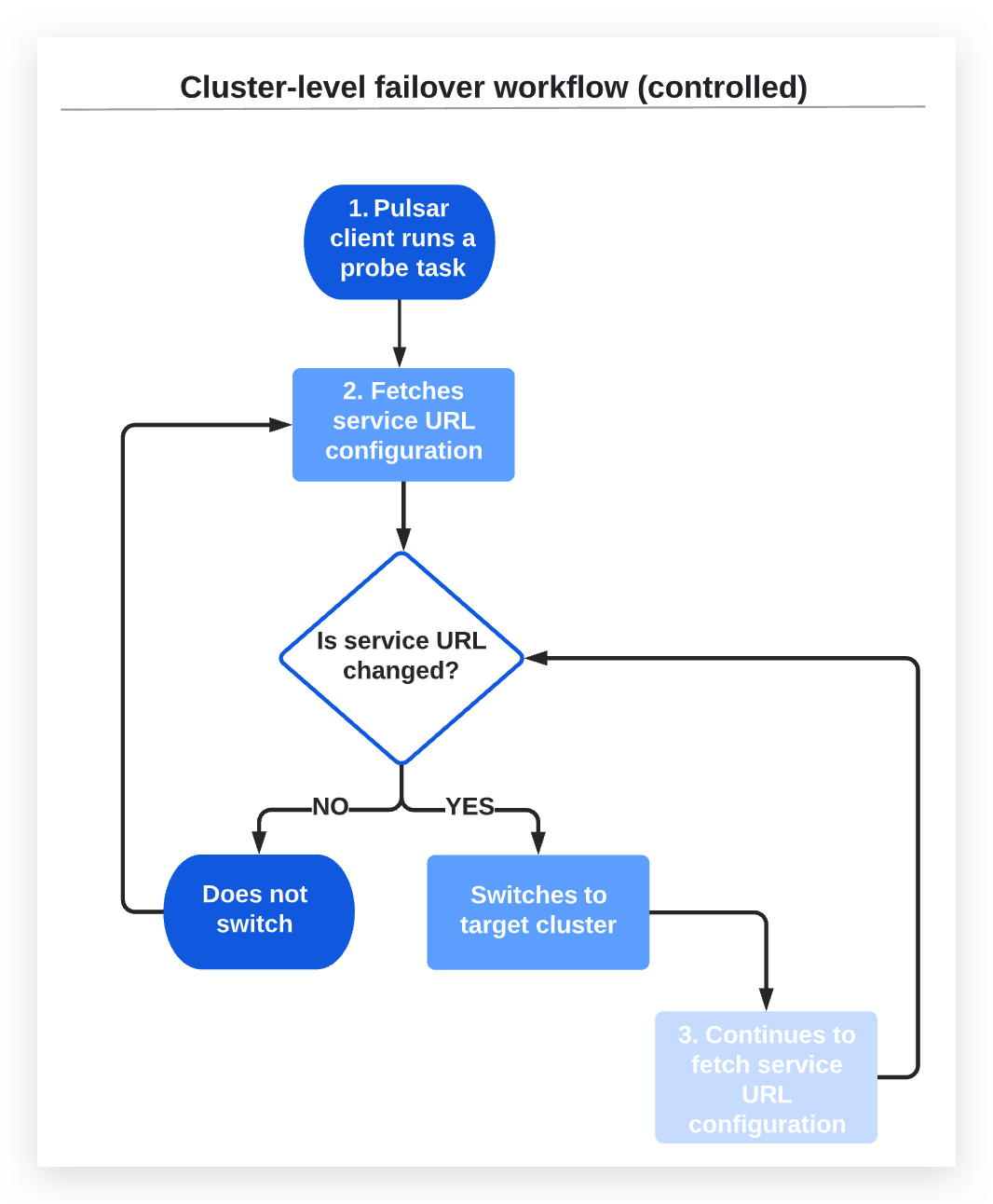
-
The Pulsar client runs a probe task at intervals defined in
checkInterval. -
The probe task fetches the service URL configuration from the URL provider service, which is configured by
urlProvider.2a) If the service URL configuration is changed, the probe task switches to the target cluster without checking the health status of the target cluster.
2b) If the service URL configuration is not changed, the Pulsar client does not perform the switchover.
-
If the Pulsar client switches to the target cluster, the probe task continues to fetch service URL configuration from the URL provider service at intervals defined in
checkInterval.3a) If the service URL configuration is changed, the probe task switches to the target cluster without checking the health status of the target cluster.
3b) If the service URL configuration is not changed, it does not perform the switchover.
Producer
In Pulsar, producers write messages to topics. Once you've instantiated a PulsarClient object (as in the section above), you can create a Producer for a specific Pulsar topic.
Producer<byte[]> producer = client.newProducer()
.topic("my-topic")
.create();
// You can then send messages to the broker and topic you specified:
producer.send("My message".getBytes());
By default, producers produce messages that consist of byte arrays. You can produce different types by specifying a message schema.
Producer<String> stringProducer = client.newProducer(Schema.STRING)
.topic("my-topic")
.create();
stringProducer.send("My message");
Make sure that you close your producers, consumers, and clients when you do not need them.
Close operations can also be asynchronous:
Configure producer
If you instantiate a Producer object by specifying only a topic name as the example above, the default configuration of producer is used.
If you create a producer, you can use the loadConf configuration. The following parameters are available in loadConf.
| Name | Type | Description | Default |
|---|---|---|---|
topicName | string | Topic name | null |
producerName | string | Producer name | null |
sendTimeoutMs | long | Message send timeout in ms. If a message is not acknowledged by a server before the sendTimeout expires, an error occurs. | 30000 |
blockIfQueueFull | boolean | If it is set to true, when the outgoing message queue is full, the Send and SendAsync methods of producer block, rather than failing and throwing errors. If it is set to false, when the outgoing message queue is full, the Send and SendAsync methods of producer fail and ProducerQueueIsFullError exceptions occur.The MaxPendingMessages parameter determines the size of the outgoing message queue. | false |
maxPendingMessages | int | The maximum size of a queue holding pending messages. For example, a message waiting to receive an acknowledgment from a broker. By default, when the queue is full, all calls to the Send and SendAsync methods fail unless you set BlockIfQueueFull to true. | 1000 |
maxPendingMessagesAcrossPartitions | int | The maximum number of pending messages across partitions. Use the setting to lower the max pending messages for each partition ( #setMaxPendingMessages(int)) if the total number exceeds the configured value. | 50000 |
messageRoutingMode | MessageRoutingMode | Message routing logic for producers on partitioned topics. Apply the logic only when setting no key on messages. Available options are as follows: pulsar.RoundRobinDistribution: round robinpulsar.UseSinglePartition: publish all messages to a single partitionpulsar.CustomPartition: a custom partitioning scheme | pulsar.RoundRobinDistribution |
hashingScheme | HashingScheme | Hashing function determining the partition where you publish a particular message (partitioned topics only). Available options are as follows: pulsar.JavastringHash: the equivalent of string.hashCode() in Javapulsar.Murmur3_32Hash: applies the Murmur3 hashing functionpulsar.BoostHash: applies the hashing function from C++'s Boost library | HashingScheme.JavastringHash |
cryptoFailureAction | ProducerCryptoFailureAction | Producer should take action when encryption fails. | ProducerCryptoFailureAction.FAIL |
batchingMaxPublishDelayMicros | long | Batching time period of sending messages. | TimeUnit.MILLISECONDS.toMicros(1) |
batchingMaxMessages | int | The maximum number of messages permitted in a batch. | 1000 |
batchingEnabled | boolean | Enable batching of messages. | true |
chunkingEnabled | boolean | Enable chunking of messages. | false |
compressionType | CompressionType | Message data compression type used by a producer. Available options: LZ4ZLIBZSTDSNAPPY | No compression |
initialSubscriptionName | string | Use this configuration to automatically create an initial subscription when creating a topic. If this field is not set, the initial subscription is not created. | null |
You can configure parameters if you do not want to use the default configuration.
For a full list, see the Javadoc for the ProducerBuilder class. The following is an example.
Producer<byte[]> producer = client.newProducer()
.topic("my-topic")
.batchingMaxPublishDelay(10, TimeUnit.MILLISECONDS)
.sendTimeout(10, TimeUnit.SECONDS)
.blockIfQueueFull(true)
.create();
Message routing
When using partitioned topics, you can specify the routing mode whenever you publish messages using a producer. For more information on specifying a routing mode using the Java client, see the Partitioned Topics cookbook.
Async send
You can publish messages asynchronously using the Java client. With async send, the producer puts the message in a blocking queue and returns it immediately. Then the client library sends the message to the broker in the background. If the queue is full (max size configurable), the producer is blocked or fails immediately when calling the API, depending on arguments passed to the producer.
The following is an example.
producer.sendAsync("my-async-message".getBytes()).thenAccept(msgId -> {
System.out.println("Message with ID " + msgId + " successfully sent");
});
As you can see from the example above, async send operations return a MessageId wrapped in a CompletableFuture.
Configure messages
In addition to a value, you can set additional items on a given message:
producer.newMessage()
.key("my-message-key")
.value("my-async-message".getBytes())
.property("my-key", "my-value")
.property("my-other-key", "my-other-value")
.send();
You can terminate the builder chain with sendAsync() and get a future return.
Enable chunking
Message chunking enables Pulsar to process large payload messages by splitting the message into chunks at the producer side and aggregating chunked messages at the consumer side.
The message chunking feature is OFF by default. The following is an example about how to enable message chunking when creating a producer.
Producer<byte[]> producer = client.newProducer()
.topic(topic)
.enableChunking(true)
.enableBatching(false)
.create();
By default, producer chunks the large message based on max message size (maxMessageSize) configured at broker (eg: 5MB). However, client can also configure max chunked size using producer configuration chunkMaxMessageSize.
Note: To enable chunking, you need to disable batching (
enableBatching=false) concurrently.
Intercept messages
ProducerInterceptors intercept and possibly mutate messages received by the producer before they are published to the brokers.
The interface has three main events:
eligiblechecks if the interceptor can be applied to the message.beforeSendis triggered before the producer sends the message to the broker. You can modify messages within this event.onSendAcknowledgementis triggered when the message is acknowledged by the broker or the sending failed.
To intercept messages, you can add one or multiple ProducerInterceptors when creating a Producer as follows.
Producer<byte[]> producer = client.newProducer()
.topic(topic)
.intercept(new ProducerInterceptor {
@Override
boolean eligible(Message message) {
return true; // process all messages
}
@Override
Message beforeSend(Producer producer, Message message) {
// user-defined processing logic
}
@Override
void onSendAcknowledgement(Producer producer, Message message, MessageId msgId, Throwable exception) {
// user-defined processing logic
}
})
.create();
If you are using multiple interceptors, they apply in the order they are passed to the intercept method.
Consumer
In Pulsar, consumers subscribe to topics and handle messages that producers publish to those topics. You can instantiate a new consumer by first instantiating a PulsarClient object and passing it a URL for a Pulsar broker (as above).
Once you've instantiated a PulsarClient object, you can create a Consumer by specifying a topic and a subscription.
Consumer consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.subscribe();
The subscribe method will auto subscribe the consumer to the specified topic and subscription. One way to make the consumer listen on the topic is to set up a while loop. In this example loop, the consumer listens for messages, prints the contents of any received message, and then acknowledges that the message has been processed. If the processing logic fails, you can use negative acknowledgement to redeliver the message later.
while (true) {
// Wait for a message
Message msg = consumer.receive();
try {
// Do something with the message
System.out.println("Message received: " + new String(msg.getData()));
// Acknowledge the message
consumer.acknowledge(msg);
} catch (Exception e) {
// Message failed to process, redeliver later
consumer.negativeAcknowledge(msg);
}
}
If you don't want to block your main thread but constantly listen for new messages, consider using a MessageListener. The MessageListener uses a thread pool inside the client. You can set the number of threads for message listeners in the ClientBuilder.
MessageListener myMessageListener = (consumer, msg) -> {
try {
System.out.println("Message received: " + new String(msg.getData()));
consumer.acknowledge(msg);
} catch (Exception e) {
consumer.negativeAcknowledge(msg);
}
}
Consumer consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.messageListener(myMessageListener)
.subscribe();
Configure consumer
If you instantiate a Consumer object by specifying only a topic and subscription name as in the example above, the consumer uses the default configuration.
When you create a consumer, you can use the loadConf configuration. The following parameters are available in loadConf.
| Name | Type | Description | Default |
|---|---|---|---|
topicNames | Set<String> | Topic name | Sets.newTreeSet() |
topicsPattern | Pattern | Topic pattern | None |
subscriptionName | String | Subscription name | None |
subscriptionType | SubscriptionType | Subscription type Four subscription types are available: | SubscriptionType.Exclusive |
receiverQueueSize | int | Size of a consumer's receiver queue. For example, the number of messages accumulated by a consumer before an application calls Receive. A value higher than the default value increases consumer throughput, though at the expense of more memory utilization. | 1000 |
acknowledgementsGroupTimeMicros | long | Group a consumer acknowledgment for a specified time. By default, a consumer uses 100ms grouping time to send out acknowledgments to a broker. Setting a group time of 0 sends out acknowledgments immediately. A longer ack group time is more efficient at the expense of a slight increase in message re-deliveries after a failure. | TimeUnit.MILLISECONDS.toMicros(100) |
negativeAckRedeliveryDelayMicros | long | Delay to wait before redelivering messages that failed to be processed. When an application uses Consumer#negativeAcknowledge(Message), failed messages are redelivered after a fixed timeout. | TimeUnit.MINUTES.toMicros(1) |
maxTotalReceiverQueueSizeAcrossPartitions | int | The max total receiver queue size across partitions. This setting reduces the receiver queue size for individual partitions if the total receiver queue size exceeds this value. | 50000 |
consumerName | String | Consumer name | null |
ackTimeoutMillis | long | Timeout of unacked messages | 0 |
tickDurationMillis | long | Granularity of the ack-timeout redelivery. Using an higher tickDurationMillis reduces the memory overhead to track messages when setting ack-timeout to a bigger value (for example, 1 hour). | 1000 |
priorityLevel | int | Priority level for a consumer to which a broker gives more priority while dispatching messages in Shared subscription type. The broker follows descending priorities. For example, 0=max-priority, 1, 2,... In Shared subscription type, the broker first dispatches messages to the max priority level consumers if they have permits. Otherwise, the broker considers next priority level consumers. Example 1 If a subscription has consumerA with priorityLevel 0 and consumerB with priorityLevel 1, then the broker only dispatches messages to consumerA until it runs out permits and then starts dispatching messages to consumerB.Example 2 Consumer Priority, Level, Permits C1, 0, 2 C2, 0, 1 C3, 0, 1 C4, 1, 2 C5, 1, 1 Order in which a broker dispatches messages to consumers is: C1, C2, C3, C1, C4, C5, C4. | 0 |
cryptoFailureAction | ConsumerCryptoFailureAction | Consumer should take action when it receives a message that can not be decrypted. The decompression of message fails. If messages contain batch messages, a client is not be able to retrieve individual messages in batch. Delivered encrypted message contains EncryptionContext which contains encryption and compression information in it using which application can decrypt consumed message payload. | |
properties | SortedMap<String, String> | A name or value property of this consumer.properties is application defined metadata attached to a consumer. When getting a topic stats, associate this metadata with the consumer stats for easier identification. | new TreeMap() |
readCompacted | boolean | If enabling readCompacted, a consumer reads messages from a compacted topic rather than reading a full message backlog of a topic.A consumer only sees the latest value for each key in the compacted topic, up until reaching the point in the topic message when compacting backlog. Beyond that point, send messages as normal. Only enabling readCompacted on subscriptions to persistent topics, which have a single active consumer (like failure or exclusive subscriptions). Attempting to enable it on subscriptions to non-persistent topics or on shared subscriptions leads to a subscription call throwing a PulsarClientException. | false |
subscriptionInitialPosition | SubscriptionInitialPosition | Initial position at which to set cursor when subscribing to a topic at first time. | SubscriptionInitialPosition.Latest |
patternAutoDiscoveryPeriod | int | Topic auto discovery period when using a pattern for topic's consumer. The default and minimum value is 1 minute. | 1 |
regexSubscriptionMode | RegexSubscriptionMode | When subscribing to a topic using a regular expression, you can pick a certain type of topics. | RegexSubscriptionMode.PersistentOnly |
deadLetterPolicy | DeadLetterPolicy | Dead letter policy for consumers. By default, some messages are probably redelivered many times, even to the extent that it never stops. By using the dead letter mechanism, messages have the max redelivery count. When exceeding the maximum number of redeliveries, messages are sent to the Dead Letter Topic and acknowledged automatically. You can enable the dead letter mechanism by setting deadLetterPolicy.Example client.newConsumer()Default dead letter topic name is \{TopicName\}-\{Subscription\}-DLQ.To set a custom dead letter topic name: client.newConsumer()When specifying the dead letter policy while not specifying ackTimeoutMillis, you can set the ack timeout to 30000 millisecond. | None |
autoUpdatePartitions | boolean | If autoUpdatePartitions is enabled, a consumer subscribes to partition increasement automatically.Note: this is only for partitioned consumers. | true |
replicateSubscriptionState | boolean | If replicateSubscriptionState is enabled, a subscription state is replicated to geo-replicated clusters. | false |
negativeAckRedeliveryBackoff | RedeliveryBackoff | Interface for custom message is negativeAcked policy. You can specify RedeliveryBackoff for a consumer. | MultiplierRedeliveryBackoff |
ackTimeoutRedeliveryBackoff | RedeliveryBackoff | Interface for custom message is ackTimeout policy. You can specify RedeliveryBackoff for a consumer. | MultiplierRedeliveryBackoff |
autoAckOldestChunkedMessageOnQueueFull | boolean | Whether to automatically acknowledge pending chunked messages when the threashold of maxPendingChunkedMessage is reached. If set to false, these messages will be redelivered by their broker. | true |
maxPendingChunkedMessage | int | The maximum size of a queue holding pending chunked messages. When the threshold is reached, the consumer drops pending messages to optimize memory utilization. | 10 |
expireTimeOfIncompleteChunkedMessageMillis | long | The time interval to expire incomplete chunks if a consumer fails to receive all the chunks in the specified time period. The default value is 1 minute. | 60000 |
You can configure parameters if you do not want to use the default configuration. For a full list, see the Javadoc for the ConsumerBuilder class.
The following is an example.
Consumer consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.ackTimeout(10, TimeUnit.SECONDS)
.subscriptionType(SubscriptionType.Exclusive)
.subscribe();
Async receive
The receive method receives messages synchronously (the consumer process is blocked until a message is available). You can also use async receive, which returns a CompletableFuture object immediately once a new message is available.
The following is an example.
CompletableFuture<Message> asyncMessage = consumer.receiveAsync();
Async receive operations return a Message wrapped inside of a CompletableFuture.
Batch receive
Use batchReceive to receive multiple messages for each call.
The following is an example.
Messages messages = consumer.batchReceive();
for (Object message : messages) {
// do something
}
consumer.acknowledge(messages)
Batch receive policy limits the number and bytes of messages in a single batch. You can specify a timeout to wait for enough messages. The batch receive is completed if any of the following conditions are met: enough number of messages, bytes of messages, wait timeout.
Consumer consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.batchReceivePolicy(BatchReceivePolicy.builder()
.maxNumMessages(100)
.maxNumBytes(1024 * 1024)
.timeout(200, TimeUnit.MILLISECONDS)
.build())
.subscribe();
The default batch receive policy is:
BatchReceivePolicy.builder()
.maxNumMessage(-1)
.maxNumBytes(10 * 1024 * 1024)
.timeout(100, TimeUnit.MILLISECONDS)
.build();
Configure chunking
You can limit the maximum number of chunked messages a consumer maintains concurrently by configuring the maxPendingChunkedMessage and autoAckOldestChunkedMessageOnQueueFull parameters. When the threshold is reached, the consumer drops pending messages by silently acknowledging them or asking the broker to redeliver them later. The expireTimeOfIncompleteChunkedMessage parameter decides the time interval to expire incomplete chunks if the consumer fails to receive all chunks of a message within the specified time period.
The following is an example of how to configure message chunking.
Consumer<byte[]> consumer = client.newConsumer()
.topic(topic)
.subscriptionName("test")
.autoAckOldestChunkedMessageOnQueueFull(true)
.maxPendingChunkedMessage(100)
.expireTimeOfIncompleteChunkedMessage(10, TimeUnit.MINUTES)
.subscribe();
Negative acknowledgment redelivery backoff
The RedeliveryBackoff introduces a redelivery backoff mechanism. You can achieve redelivery with different delays by setting redeliveryCount of messages.
Consumer consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.negativeAckRedeliveryBackoff(MultiplierRedeliveryBackoff.builder()
.minDelayMs(1000)
.maxDelayMs(60 * 1000)
.build())
.subscribe();
Acknowledgement timeout redelivery backoff
The RedeliveryBackoff introduces a redelivery backoff mechanism. You can redeliver messages with different delays by setting the number
of times the messages is retried.
Consumer consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.ackTimeout(10, TimeUnit.SECOND)
.ackTimeoutRedeliveryBackoff(MultiplierRedeliveryBackoff.builder()
.minDelayMs(1000)
.maxDelayMs(60000)
.multiplier(2)
.build())
.subscribe();
The message redelivery behavior should be as follows.
| Redelivery count | Redelivery delay |
|---|---|
| 1 | 10 + 1 seconds |
| 2 | 10 + 2 seconds |
| 3 | 10 + 4 seconds |
| 4 | 10 + 8 seconds |
| 5 | 10 + 16 seconds |
| 6 | 10 + 32 seconds |
| 7 | 10 + 60 seconds |
| 8 | 10 + 60 seconds |
- The
negativeAckRedeliveryBackoffdoes not work withconsumer.negativeAcknowledge(MessageId messageId)because you are not able to get the redelivery count from the message ID. - If a consumer crashes, it triggers the redelivery of unacked messages. In this case,
RedeliveryBackoffdoes not take effect and the messages might get redelivered earlier than the delay time from the backoff.
Multi-topic subscriptions
In addition to subscribing a consumer to a single Pulsar topic, you can also subscribe to multiple topics simultaneously using multi-topic subscriptions. To use multi-topic subscriptions you can supply either a regular expression (regex) or a List of topics. If you select topics via regex, all topics must be within the same Pulsar namespace.
The followings are some examples.
import org.apache.pulsar.client.api.Consumer;
import org.apache.pulsar.client.api.PulsarClient;
import java.util.Arrays;
import java.util.List;
import java.util.regex.Pattern;
ConsumerBuilder consumerBuilder = pulsarClient.newConsumer()
.subscriptionName(subscription);
// Subscribe to all topics in a namespace
Pattern allTopicsInNamespace = Pattern.compile("public/default/.*");
Consumer allTopicsConsumer = consumerBuilder
.topicsPattern(allTopicsInNamespace)
.subscribe();
// Subscribe to a subsets of topics in a namespace, based on regex
Pattern someTopicsInNamespace = Pattern.compile("public/default/foo.*");
Consumer allTopicsConsumer = consumerBuilder
.topicsPattern(someTopicsInNamespace)
.subscribe();
In the above example, the consumer subscribes to the persistent topics that can match the topic name pattern. If you want the consumer subscribes to all persistent and non-persistent topics that can match the topic name pattern, set subscriptionTopicsMode to RegexSubscriptionMode.AllTopics.
Pattern pattern = Pattern.compile("public/default/.*");
pulsarClient.newConsumer()
.subscriptionName("my-sub")
.topicsPattern(pattern)
.subscriptionTopicsMode(RegexSubscriptionMode.AllTopics)
.subscribe();
By default, the subscriptionTopicsMode of the consumer is PersistentOnly. Available options of subscriptionTopicsMode are PersistentOnly, NonPersistentOnly, and AllTopics.
You can also subscribe to an explicit list of topics (across namespaces if you wish):
List<String> topics = Arrays.asList(
"topic-1",
"topic-2",
"topic-3"
);
Consumer multiTopicConsumer = consumerBuilder
.topics(topics)
.subscribe();
// Alternatively:
Consumer multiTopicConsumer = consumerBuilder
.topic(
"topic-1",
"topic-2",
"topic-3"
)
.subscribe();
You can also subscribe to multiple topics asynchronously using the subscribeAsync method rather than the synchronous subscribe method. The following is an example.
Pattern allTopicsInNamespace = Pattern.compile("persistent://public/default.*");
consumerBuilder
.topics(topics)
.subscribeAsync()
.thenAccept(this::receiveMessageFromConsumer);
private void receiveMessageFromConsumer(Object consumer) {
((Consumer)consumer).receiveAsync().thenAccept(message -> {
// Do something with the received message
receiveMessageFromConsumer(consumer);
});
}
Subscription types
Pulsar has various subscription types to match different scenarios. A topic can have multiple subscriptions with different subscription types. However, a subscription can only have one subscription type at a time.
A subscription is identical to the subscription name; a subscription name can specify only one subscription type at a time. To change the subscription type, you should first stop all consumers of this subscription.
Different subscription types have different message distribution types. This section describes the differences of subscription types and how to use them.
In order to better describe their differences, assume you have a topic named "my-topic", and the producer has published 10 messages.
Producer<String> producer = client.newProducer(Schema.STRING)
.topic("my-topic")
.enableBatching(false)
.create();
// 3 messages with "key-1", 3 messages with "key-2", 2 messages with "key-3" and 2 messages with "key-4"
producer.newMessage().key("key-1").value("message-1-1").send();
producer.newMessage().key("key-1").value("message-1-2").send();
producer.newMessage().key("key-1").value("message-1-3").send();
producer.newMessage().key("key-2").value("message-2-1").send();
producer.newMessage().key("key-2").value("message-2-2").send();
producer.newMessage().key("key-2").value("message-2-3").send();
producer.newMessage().key("key-3").value("message-3-1").send();
producer.newMessage().key("key-3").value("message-3-2").send();
producer.newMessage().key("key-4").value("message-4-1").send();
producer.newMessage().key("key-4").value("message-4-2").send();
Exclusive
Create a new consumer and subscribe with the Exclusive subscription type.
Consumer consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Exclusive)
.subscribe()
Only the first consumer is allowed to the subscription, other consumers receive an error. The first consumer receives all 10 messages, and the consuming order is the same as the producing order.
If topic is a partitioned topic, the first consumer subscribes to all partitioned topics, other consumers are not assigned with partitions and receive an error.
Failover
Create new consumers and subscribe with theFailover subscription type.
Consumer consumer1 = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Failover)
.subscribe()
Consumer consumer2 = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Failover)
.subscribe()
//conumser1 is the active consumer, consumer2 is the standby consumer.
//consumer1 receives 5 messages and then crashes, consumer2 takes over as an active consumer.
Multiple consumers can attach to the same subscription, yet only the first consumer is active, and others are standby. When the active consumer is disconnected, messages will be dispatched to one of standby consumers, and the standby consumer then becomes active consumer.
If the first active consumer is disconnected after receiving 5 messages, the standby consumer becomes active consumer. Consumer1 will receive:
("key-1", "message-1-1")
("key-1", "message-1-2")
("key-1", "message-1-3")
("key-2", "message-2-1")
("key-2", "message-2-2")
consumer2 will receive:
("key-2", "message-2-3")
("key-3", "message-3-1")
("key-3", "message-3-2")
("key-4", "message-4-1")
("key-4", "message-4-2")
If a topic is a partitioned topic, each partition has only one active consumer, messages of one partition are distributed to only one consumer, and messages of multiple partitions are distributed to multiple consumers.
Shared
Create new consumers and subscribe with Shared subscription type.
Consumer consumer1 = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.subscribe()
Consumer consumer2 = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Shared)
.subscribe()
//Both consumer1 and consumer2 are active consumers.
In Shared subscription type, multiple consumers can attach to the same subscription and messages are delivered in a round robin distribution across consumers.
If a broker dispatches only one message at a time, consumer1 receives the following information.
("key-1", "message-1-1")
("key-1", "message-1-3")
("key-2", "message-2-2")
("key-3", "message-3-1")
("key-4", "message-4-1")
consumer2 receives the following information.
("key-1", "message-1-2")
("key-2", "message-2-1")
("key-2", "message-2-3")
("key-3", "message-3-2")
("key-4", "message-4-2")
Shared subscription is different from Exclusive and Failover subscription types. Shared subscription has better flexibility, but cannot provide order guarantee.
Key_shared
This is a new subscription type since 2.4.0 release. Create new consumers and subscribe with Key_Shared subscription type.
Consumer consumer1 = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Key_Shared)
.subscribe()
Consumer consumer2 = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.subscriptionType(SubscriptionType.Key_Shared)
.subscribe()
//Both consumer1 and consumer2 are active consumers.
Just like in Shared subscription, all consumers in Key_Shared subscription type can attach to the same subscription. But Key_Shared subscription type is different from the Shared subscription. In Key_Shared subscription type, messages with the same key are delivered to only one consumer in order. The possible distribution of messages between different consumers (by default we do not know in advance which keys will be assigned to a consumer, but a key will only be assigned to a consumer at the same time).
consumer1 receives the following information.
("key-1", "message-1-1")
("key-1", "message-1-2")
("key-1", "message-1-3")
("key-3", "message-3-1")
("key-3", "message-3-2")
consumer2 receives the following information.
("key-2", "message-2-1")
("key-2", "message-2-2")
("key-2", "message-2-3")
("key-4", "message-4-1")
("key-4", "message-4-2")
If batching is enabled at the producer side, messages with different keys are added to a batch by default. The broker will dispatch the batch to the consumer, so the default batch mechanism may break the Key_Shared subscription guaranteed message distribution semantics. The producer needs to use the KeyBasedBatcher.
Producer producer = client.newProducer()
.topic("my-topic")
.batcherBuilder(BatcherBuilder.KEY_BASED)
.create();
Or the producer can disable batching.
Producer producer = client.newProducer()
.topic("my-topic")
.enableBatching(false)
.create();
If the message key is not specified, messages without keys are dispatched to one consumer in order by default.
Intercept messages
ConsumerInterceptors intercept and possibly mutate messages received by the consumer.
The interface has six main events:
beforeConsumeis triggered before the message is returned byreceive()orreceiveAsync(). You can modify messages within this event.onAcknowledgeis triggered before the consumer sends the acknowledgement to the broker.onAcknowledgeCumulativeis triggered before the consumer sends the cumulative acknowledgement to the broker.onNegativeAcksSendis triggered when a redelivery from a negative acknowledgement occurs.onAckTimeoutSendis triggered when a redelivery from an acknowledgement timeout occurs.onPartitionsChangeis triggered when the partitions of the (partitioned) topic change.
To intercept messages, you can add one or multiple ConsumerInterceptors when creating a Consumer as follows.
Consumer<String> consumer = client.newConsumer()
.topic("my-topic")
.subscriptionName("my-subscription")
.intercept(new ConsumerInterceptor<String> {
@Override
public Message<String> beforeConsume(Consumer<String> consumer, Message<String> message) {
// user-defined processing logic
}
@Override
public void onAcknowledge(Consumer<String> consumer, MessageId messageId, Throwable cause) {
// user-defined processing logic
}
@Override
public void onAcknowledgeCumulative(Consumer<String> consumer, MessageId messageId, Throwable cause) {
// user-defined processing logic
}
@Override
public void onNegativeAcksSend(Consumer<String> consumer, Set<MessageId> messageIds) {
// user-defined processing logic
}
@Override
public void onAckTimeoutSend(Consumer<String> consumer, Set<MessageId> messageIds) {
// user-defined processing logic
}
@Override
public void onPartitionsChange(String topicName, int partitions) {
// user-defined processing logic
}
})
.subscribe();
If you are using multiple interceptors, they apply in the order they are passed to the intercept method.
Reader
With the reader interface, Pulsar clients can "manually position" themselves within a topic and read all messages from a specified message onward. The Pulsar API for Java enables you to create Reader objects by specifying a topic and a MessageId.
The following is an example.
byte[] msgIdBytes = // Some message ID byte array
MessageId id = MessageId.fromByteArray(msgIdBytes);
Reader reader = pulsarClient.newReader()
.topic(topic)
.startMessageId(id)
.create();
while (true) {
Message message = reader.readNext();
// Process message
}
In the example above, a Reader object is instantiated for a specific topic and message (by ID); the reader iterates over each message in the topic after the message is identified by msgIdBytes (how that value is obtained depends on the application).
The code sample above shows pointing the Reader object to a specific message (by ID), but you can also use MessageId.earliest to point to the earliest available message on the topic of MessageId.latest to point to the most recent available message.
Configure reader
When you create a reader, you can use the loadConf configuration. The following parameters are available in loadConf.
| Name | Type | Description | Default |
|---|---|---|---|
topicName | String | Topic name. | None |
receiverQueueSize | int | Size of a consumer's receiver queue. For example, the number of messages that can be accumulated by a consumer before an application calls Receive.A value higher than the default value increases consumer throughput, though at the expense of more memory utilization. | 1000 |
readerListener | ReaderListener<T> | A listener that is called for message received. | None |
readerName | String | Reader name. | null |
subscriptionName | String | Subscription name | When there is a single topic, the default subscription name is "reader-" + 10-digit UUID.When there are multiple topics, the default subscription name is "multiTopicsReader-" + 10-digit UUID. |
subscriptionRolePrefix | String | Prefix of subscription role. | null |
cryptoKeyReader | CryptoKeyReader | Interface that abstracts the access to a key store. | null |
cryptoFailureAction | ConsumerCryptoFailureAction | Consumer should take action when it receives a message that can not be decrypted. The message decompression fails. If messages contain batch messages, a client is not be able to retrieve individual messages in batch. Delivered encrypted message contains EncryptionContext which contains encryption and compression information in it using which application can decrypt consumed message payload. | |
readCompacted | boolean | If enabling readCompacted, a consumer reads messages from a compacted topic rather than a full message backlog of a topic.A consumer only sees the latest value for each key in the compacted topic, up until reaching the point in the topic message when compacting backlog. Beyond that point, send messages as normal. readCompacted can only be enabled on subscriptions to persistent topics, which have a single active consumer (for example, failure or exclusive subscriptions). Attempting to enable it on subscriptions to non-persistent topics or on shared subscriptions leads to a subscription call throwing a PulsarClientException. | false |
resetIncludeHead | boolean | If set to true, the first message to be returned is the one specified by messageId.If set to false, the first message to be returned is the one next to the message specified by messageId. | false |
Sticky key range reader
In sticky key range reader, broker will only dispatch messages which hash of the message key contains by the specified key hash range. Multiple key hash ranges can be specified on a reader.
The following is an example to create a sticky key range reader.
pulsarClient.newReader()
.topic(topic)
.startMessageId(MessageId.earliest)
.keyHashRange(Range.of(0, 10000), Range.of(20001, 30000))
.create();
Total hash range size is 65536, so the max end of the range should be less than or equal to 65535.
TableView
The TableView interface serves an encapsulated access pattern, providing a continuously updated key-value map view of the compacted topic data. Messages without keys will be ignored.
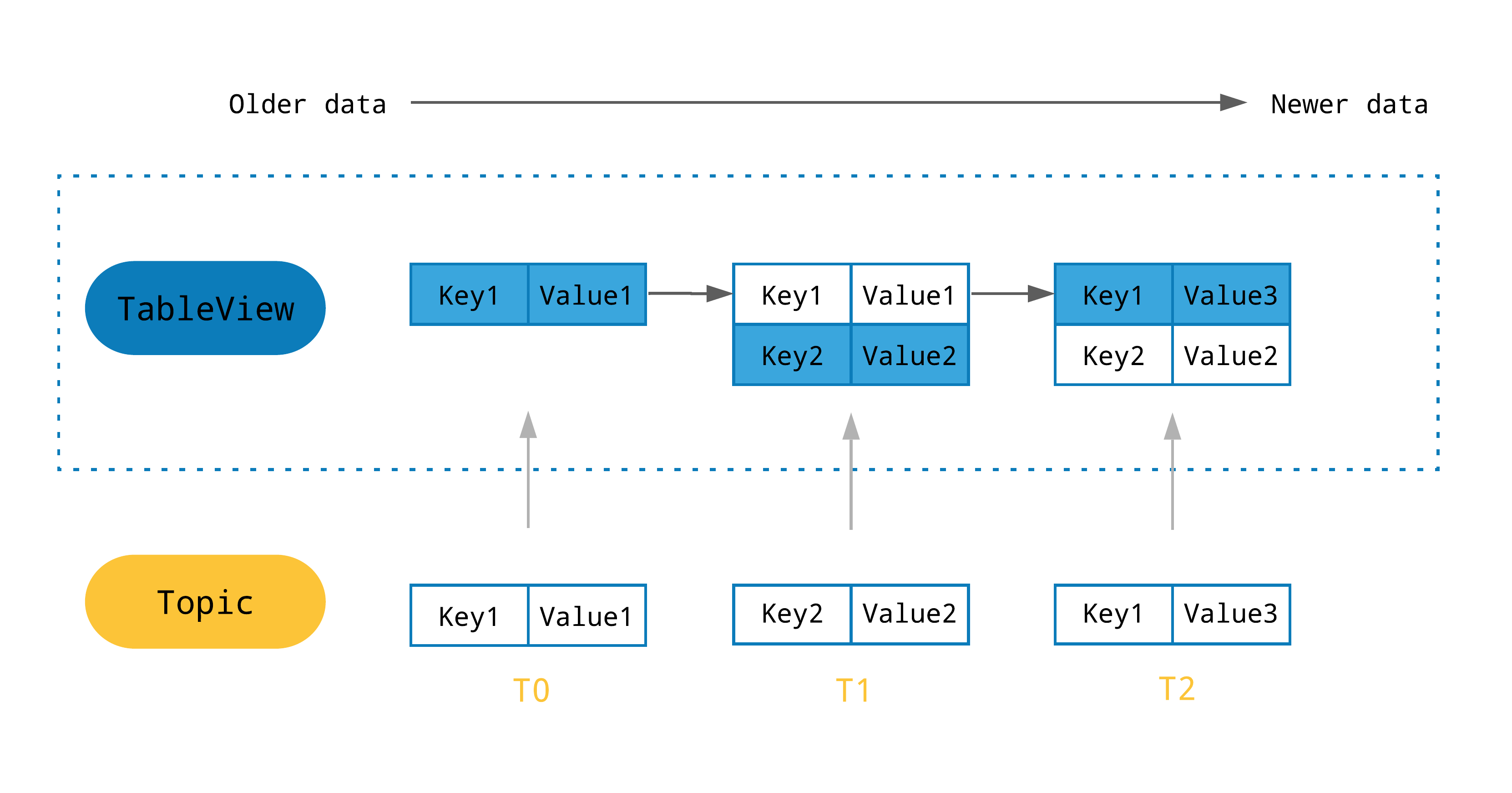
With TableView, Pulsar clients can fetch all the message updates from a topic and construct a map with the latest values of each key. These values can then be used to build a local cache of data. In addition, you can register consumers with the TableView by specifying a listener to perform a scan of the map and then receive notifications when new messages are received. Consequently, event handling can be triggered to serve use cases, such as event-driven applications and message monitoring.
Each TableView uses one Reader instance per partition, and reads the topic starting from the compacted view by default. It is highly recommended to enable automatic compaction by configuring the topic compaction policies for the given topic or namespace. More frequent compaction results in shorter startup times because less data is replayed to reconstruct the TableView of the topic.
The following figure illustrates the dynamic construction of a TableView updated with newer values of each key.
Configure TableView
The following is an example of how to configure a TableView.
TableView<String> tv = client.newTableViewBuilder(Schema.STRING)
.topic("my-tableview")
.create()
You can use the available parameters in the loadConf configuration or related API to customize your TableView.
| Name | Type | Required? | Description | Default |
|---|---|---|---|---|
topic | string | yes | The topic name of the TableView. | N/A |
autoUpdatePartitionInterval | int | no | The interval to check for newly added partitions. | 60 (seconds) |
Register listeners
You can register listeners for both existing messages on a topic and new messages coming into the topic by using forEachAndListen, and specify to perform operations for all existing messages by using forEach.
The following is an example of how to register listeners with TableView.
// Register listeners for all existing and incoming messages
tv.forEachAndListen((key, value) -> /*operations on all existing and incoming messages*/)
// Register action for all existing messages
tv.forEach((key, value) -> /*operations on all existing messages*/)
Schema
In Pulsar, all message data consists of byte arrays "under the hood." Message schemas enable you to use other types of data when constructing and handling messages (from simple types like strings to more complex, application-specific types). If you construct, say, a producer without specifying a schema, then the producer can only produce messages of type byte[]. The following is an example.
Producer<byte[]> producer = client.newProducer()
.topic(topic)
.create();
The producer above is equivalent to a Producer<byte[]> (in fact, you should always explicitly specify the type). If you'd like to use a producer for a different type of data, you'll need to specify a schema that informs Pulsar which data type will be transmitted over the topic.
AvroBaseStructSchema example
Let's say that you have a SensorReading class that you'd like to transmit over a Pulsar topic:
public class SensorReading {
public float temperature;
public SensorReading(float temperature) {
this.temperature = temperature;
}
// A no-arg constructor is required
public SensorReading() {
}
public float getTemperature() {
return temperature;
}
public void setTemperature(float temperature) {
this.temperature = temperature;
}
}
You could then create a Producer<SensorReading> (or Consumer<SensorReading>) like this:
Producer<SensorReading> producer = client.newProducer(JSONSchema.of(SensorReading.class))
.topic("sensor-readings")
.create();
The following schema formats are currently available for Java:
-
No schema or the byte array schema (which can be applied using
Schema.BYTES):Producer<byte[]> bytesProducer = client.newProducer(Schema.BYTES).topic("some-raw-bytes-topic").create();Or, equivalently:
Producer<byte[]> bytesProducer = client.newProducer().topic("some-raw-bytes-topic").create(); -
Stringfor normal UTF-8-encoded string data. Apply the schema usingSchema.STRING:Producer<String> stringProducer = client.newProducer(Schema.STRING).topic("some-string-topic").create(); -
Create JSON schemas for POJOs using
Schema.JSON. The following is an example.Producer<MyPojo> pojoProducer = client.newProducer(Schema.JSON(MyPojo.class)).topic("some-pojo-topic").create(); -
Generate Protobuf schemas using
Schema.PROTOBUF. The following example shows how to create the Protobuf schema and use it to instantiate a new producer:Producer<MyProtobuf> protobufProducer = client.newProducer(Schema.PROTOBUF(MyProtobuf.class)).topic("some-protobuf-topic").create(); -
Define Avro schemas with
Schema.AVRO. The following code snippet demonstrates how to create and use Avro schema.Producer<MyAvro> avroProducer = client.newProducer(Schema.AVRO(MyAvro.class)).topic("some-avro-topic").create();
ProtobufNativeSchema example
For example of ProtobufNativeSchema, see SchemaDefinition in Complex type.
Authentication
Pulsar currently supports multiple authentication schemes: TLS, Athenz, Kerberos, and JSON Web Token (JWT). You can use the Pulsar Java client with all of them.
TLS Authentication
To use TLS, enableTls method is deprecated and you need to use "pulsar+ssl://" in serviceUrl to enable, point your Pulsar client to a TLS cert path, and provide paths to cert and key files.
The following is an example.
Map<String, String> authParams = new HashMap();
authParams.put("tlsCertFile", "/path/to/client-cert.pem");
authParams.put("tlsKeyFile", "/path/to/client-key.pem");
Authentication tlsAuth = AuthenticationFactory
.create(AuthenticationTls.class.getName(), authParams);
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar+ssl://my-broker.com:6651")
.tlsTrustCertsFilePath("/path/to/cacert.pem")
.authentication(tlsAuth)
.build();
Athenz
To use Athenz as an authentication provider, you need to use TLS and provide values for four parameters in a hash:
tenantDomaintenantServiceproviderDomainprivateKey
You can also set an optional keyId. The following is an example.
Map<String, String> authParams = new HashMap();
authParams.put("tenantDomain", "shopping"); // Tenant domain name
authParams.put("tenantService", "some_app"); // Tenant service name
authParams.put("providerDomain", "pulsar"); // Provider domain name
authParams.put("privateKey", "file:///path/to/private.pem"); // Tenant private key path
authParams.put("keyId", "v1"); // Key id for the tenant private key (optional, default: "0")
Authentication athenzAuth = AuthenticationFactory
.create(AuthenticationAthenz.class.getName(), authParams);
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar+ssl://my-broker.com:6651")
.tlsTrustCertsFilePath("/path/to/cacert.pem")
.authentication(athenzAuth)
.build();
Supported pattern formats
The
privateKeyparameter supports the following three pattern formats:
file:///path/to/filefile:/path/to/filedata:application/x-pem-file;base64,<base64-encoded value>
Oauth2
The following example shows how to use Oauth2 as an authentication provider for the Pulsar Java client.
You can use the factory method to configure authentication for Pulsar Java client.
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://broker.example.com:6650/")
.authentication(
AuthenticationFactoryOAuth2.clientCredentials(this.issuerUrl, this.credentialsUrl, this.audience))
.build();
In addition, you can also use the encoded parameters to configure authentication for Pulsar Java client.
Authentication auth = AuthenticationFactory
.create(AuthenticationOAuth2.class.getName(), "{"type":"client_credentials","privateKey":"...","issuerUrl":"...","audience":"..."}");
PulsarClient client = PulsarClient.builder()
.serviceUrl("pulsar://broker.example.com:6650/")
.authentication(auth)
.build();