Pulsar geo-replication
Geo-replication is the replication of persistently stored message data across multiple clusters of a Pulsar instance.
How it works
The diagram below illustrates the process of geo-replication across Pulsar clusters:
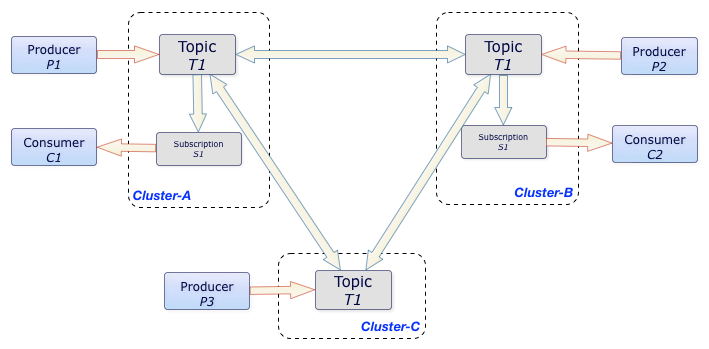
In this diagram, whenever P1, P2, and P3 producers publish messages to the T1 topic on Cluster-A, Cluster-B, and Cluster-C clusters respectively, those messages are instantly replicated across clusters. Once replicated, C1 and C2 consumers can consume those messages from their respective clusters.
Without geo-replication, C1 and C2 consumers are not able to consume messages published by P3 producer.
Geo-replication and Pulsar properties
Geo-replication must be enabled on a per-tenant basis in Pulsar. Geo-replication can be enabled between clusters only when a tenant has been created that allows access to both clusters.
Although geo-replication must be enabled between two clusters, it's actually managed at the namespace level. You must complete the following tasks to enable geo-replication for a namespace:
- Enable geo-replication namespaces
- Configure that namespace to replicate across two or more provisioned clusters
Any message published on any topic in that namespace will be replicated to all clusters in the specified set.
Local persistence and forwarding
When messages are produced on a Pulsar topic, they are first persisted in the local cluster, and then forwarded asynchronously to the remote clusters.
In normal cases, when there are no connectivity issues, messages are replicated immediately, at the same time as they are dispatched to local consumers. Typically, end-to-end delivery latency is defined by the network round-trip time (RTT) between the remote regions.
Applications can create producers and consumers in any of the clusters, even when the remote clusters are not reachable (like during a network partition).
Producers and consumers can publish messages to and consume messages from any cluster in a Pulsar instance. However, subscriptions cannot only be local to the cluster where the subscriptions are created but also can be transferred between clusters after replicated subscription is enabled. Once replicated subscription is enabled, you can keep subscription state in synchronization. Therefore, a topic can be asynchronously replicated across multiple geographical regions. In case of failover, a consumer can restart consuming messages from the failure point in a different cluster.
In the aforementioned example, the T1 topic is being replicated among three clusters, Cluster-A, Cluster-B, and Cluster-C.
All messages produced in any of the three clusters are delivered to all subscriptions in other clusters. In this case, C1 and C2 consumers will receive all messages published by P1, P2, and P3 producers. Ordering is still guaranteed on a per-producer basis.
Configuring replication
As stated in Geo-replication and Pulsar properties section, geo-replication in Pulsar is managed at the tenant level.
Granting permissions to properties
To replicate to a cluster, the tenant needs permission to use that cluster. You can grant permission to the tenant when you create it or grant later.
Specify all the intended clusters when creating a tenant:
$ bin/pulsar-admin tenants create my-tenant \
--admin-roles my-admin-role \
--allowed-clusters us-west,us-east,us-cent
To update permissions of an existing tenant, use update instead of create.
Enabling geo-replication namespaces
You can create a namespace with the following command sample.
$ bin/pulsar-admin namespaces create my-tenant/my-namespace
Initially, the namespace is not assigned to any cluster. You can assign the namespace to clusters using the set-clusters subcommand:
$ bin/pulsar-admin namespaces set-clusters my-tenant/my-namespace \
--clusters us-west,us-east,us-cent
The replication clusters for a namespace can be changed at any time, without disruption to ongoing traffic. Replication channels are immediately set up or stopped in all clusters as soon as the configuration changes.
Using topics with geo-replication
Once you've created a geo-replication namespace, any topics that producers or consumers create within that namespace will be replicated across clusters. Typically, each application will use the serviceUrl for the local cluster.
Selective replication
By default, messages are replicated to all clusters configured for the namespace. You can restrict replication selectively by specifying a replication list for a message, and then that message will be replicated only to the subset in the replication list.
The following is an example for the Java API. Note the use of the replicationClusters method when constructing the Message object:
List<String> restrictReplicationTo = Arrays.asList(
"us-west",
"us-east"
);
Producer producer = client.newProducer()
.topic("some-topic")
.create();
producer.newMessage()
.value("my-payload".getBytes())
.replicationClusters(restrictReplicationTo)
.send();
Topic stats
Topic-specific statistics for geo-replication topics are available via the pulsar-admin tool and REST API:
$ bin/pulsar-admin persistent stats persistent://my-tenant/my-namespace/my-topic
Each cluster reports its own local stats, including the incoming and outgoing replication rates and backlogs.
Deleting a geo-replication topic
Given that geo-replication topics exist in multiple regions, it's not possible to directly delete a geo-replication topic. Instead, you should rely on automatic topic garbage collection.
In Pulsar, a topic is automatically deleted when it meets the following three conditions:
- when no producers or consumers are connected to it;
- there are no subscriptions to it;
- no more messages are kept for retention. For geo-replication topics, each region uses a fault-tolerant mechanism to decide when it's safe to delete the topic locally.
You can explicitly disable topic garbage collection by setting brokerDeleteInactiveTopicsEnabled to false in your broker configuration.
To delete a geo-replication topic, close all producers and consumers on the topic, and delete all of its local subscriptions in every replication cluster. When Pulsar determines that no valid subscription for the topic remains across the system, it will garbage collect the topic.
Replicated subscriptions
Pulsar supports replicated subscriptions, so you can keep subscription state in sync, within a sub-second timeframe, in the context of a topic that is being asynchronously replicated across multiple geographical regions.
In case of failover, a consumer can restart consuming from the failure point in a different cluster.
Enabling replicated subscription
Replicated subscription is disabled by default. You can enable replicated subscription when creating a consumer.
Consumer<String> consumer = client.newConsumer(Schema.STRING)
.topic("my-topic")
.subscriptionName("my-subscription")
.replicateSubscriptionState(true)
.subscribe();
Advantages
- It is easy to implement the logic.
- You can choose to enable or disable replicated subscription.
- When you enable it, the overhead is low, and it is easy to configure.
- When you disable it, the overhead is zero.
Limitations
- When you enable replicated subscription, you're creating a consistent distributed snapshot to establish an association between message ids from different clusters. The snapshots are taken periodically. The default value is
1 second. It means that a consumer failing over to a different cluster can potentially receive 1 second of duplicates. You can also configure the frequency of the snapshot in thebroker.conffile. - Only the base line cursor position is synced in replicated subscriptions while the individual acknowledgments are not synced. This means the messages acknowledged out-of-order could end up getting delivered again, in the case of a cluster failover.