Apache Pulsar is used to store streams of event data, and the event data is structured with predefined fields. With the implementation of the Schema Registry, you can store structured data in Pulsar and query the data by using Trino (formerly Presto SQL).
As the core of Pulsar SQL, the Pulsar Trino plugin enables Trino workers within a Trino cluster to query data from Pulsar.
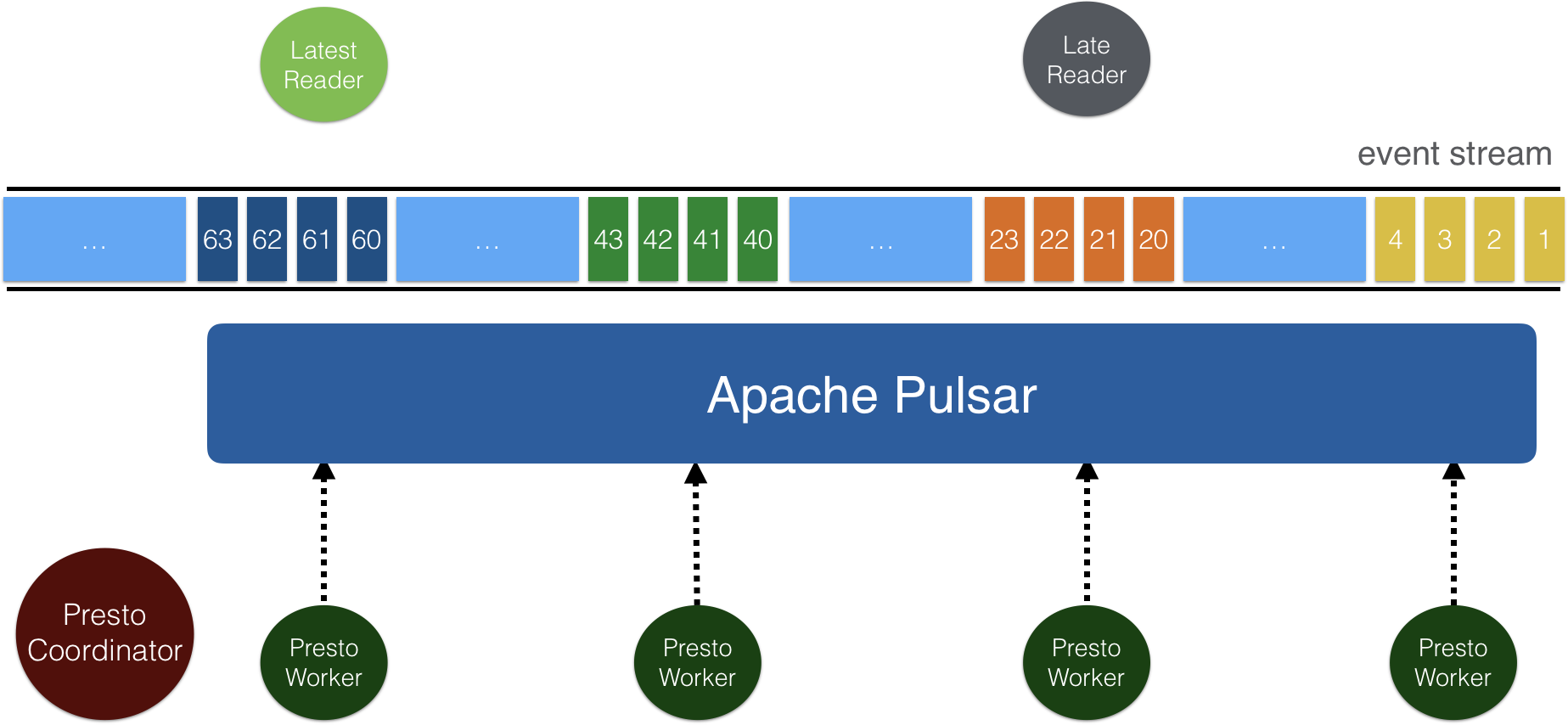
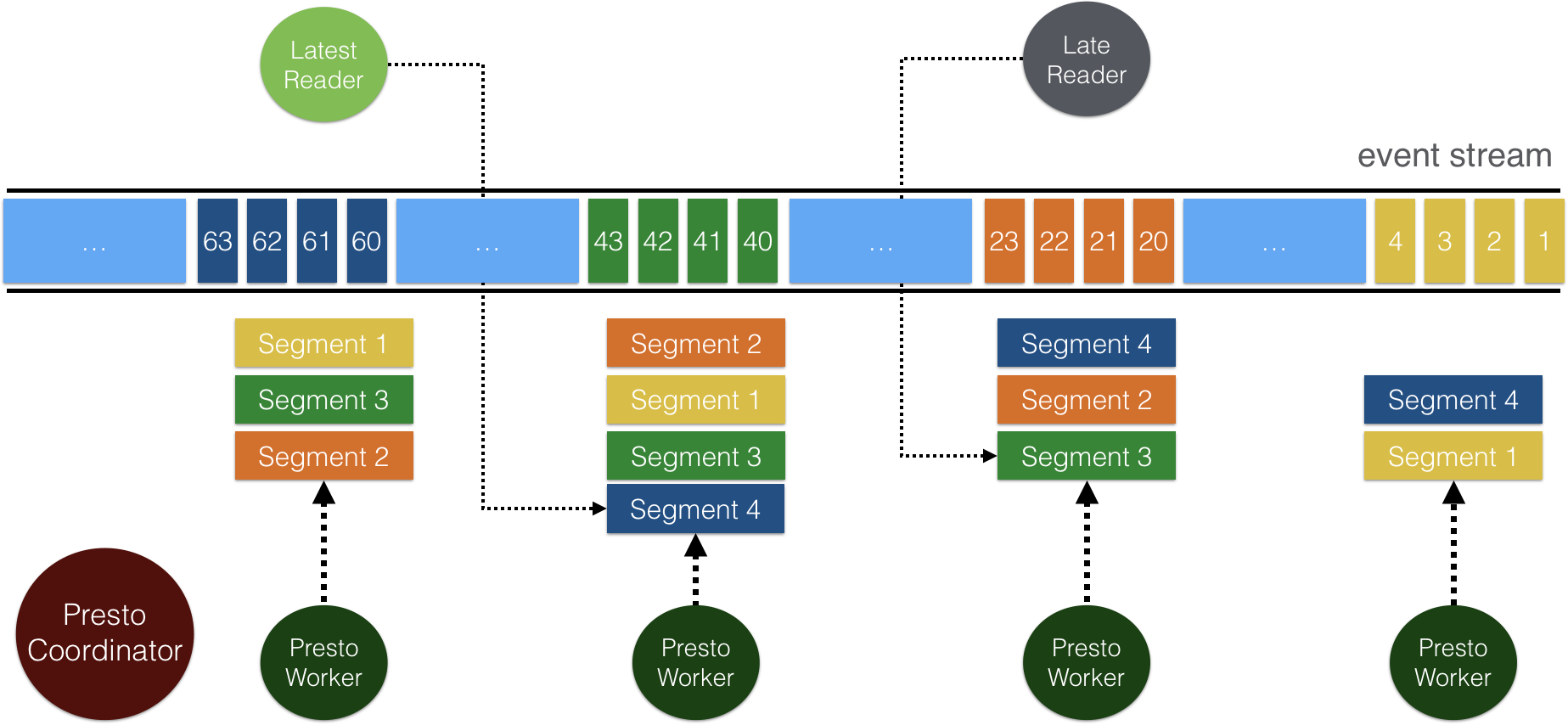
The query performance is efficient and highly scalable, because Pulsar adopts two-level-segment-based architecture.
Topics in Pulsar are stored as segments in Apache BookKeeper. Each topic segment is replicated to some BookKeeper nodes, which enables concurrent reads and high read throughput. In the Pulsar Trino connector, data is read directly from BookKeeper, so Trino workers can read concurrently from a horizontally scalable number of BookKeeper nodes.
Caveat
If you're upgrading Pulsar SQL from 2.11 or early, you should copy config files from conf/presto to trino/conf. If you're downgrading Pulsar SQL to 2.11 or early from newer versions, do verse visa.