Cluster-level failover
This chapter describes the concept, benefits, use cases, constraints, usage, working principles, and more information about the cluster-level failover.
Concept of cluster-level failover
- Automatic cluster-level failover
- Controlled cluster-level failover
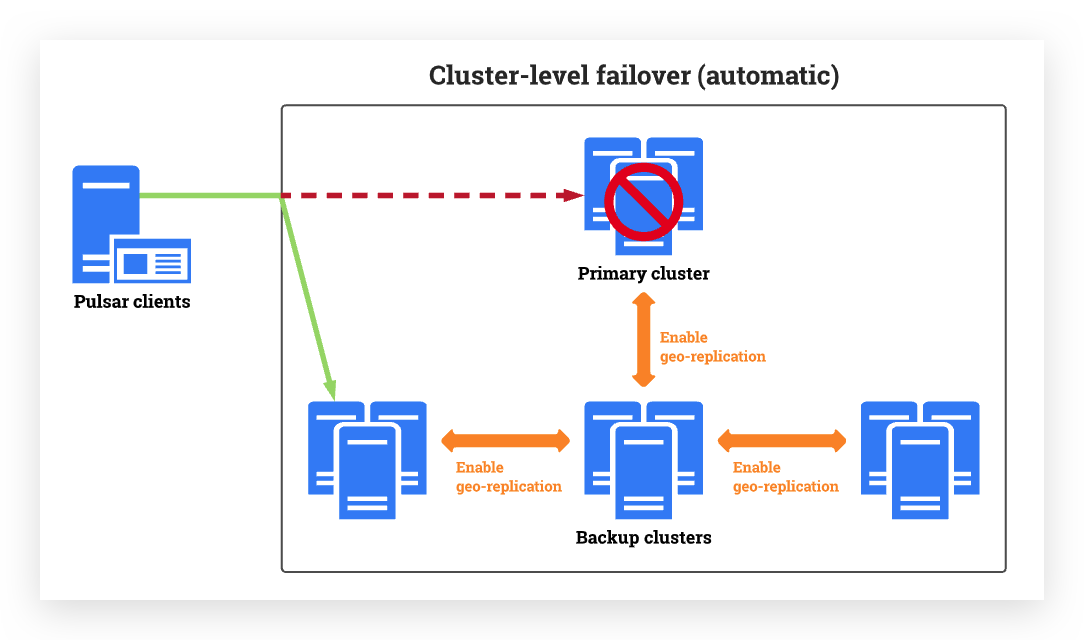
Automatic cluster-level failover supports Pulsar clients switching from a primary cluster to one or several backup clusters automatically and seamlessly when it detects a failover event based on the configured detecting policy set by users.
Controlled cluster-level failover supports Pulsar clients switching from a primary cluster to one or several backup clusters. The switchover is manually set by administrators.
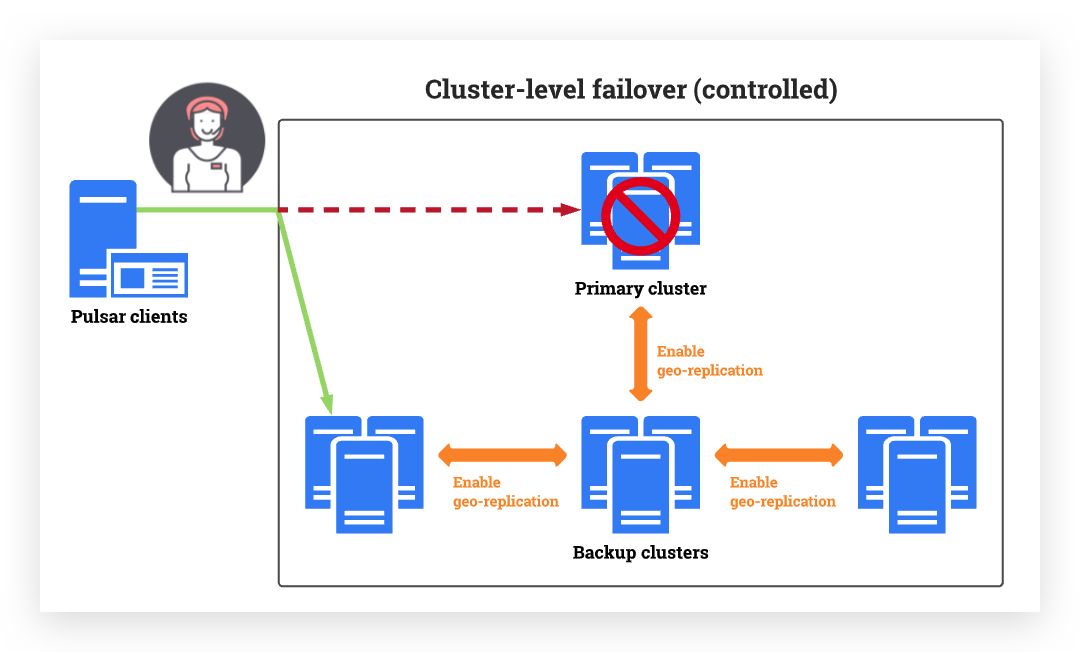
Once the primary cluster functions again, Pulsar clients can switch back to the primary cluster. Most of the time users won't even notice a thing. Users can keep using applications and services without interruptions or timeouts.
Why use cluster-level failover?
The cluster-level failover provides fault tolerance, continuous availability, and high availability together. It brings a number of benefits, including but not limited to:
-
Reduced cost
Services can be switched and recovered automatically with no data loss.
-
Simplified management
Businesses can operate on an "always-on" basis since no immediate user intervention is required.
-
Improved stability and robustness
It ensures continuous performance and minimizes service downtime.
When to use cluster-level failover?
The cluster-level failover protects your environment in a number of ways, including but not limited to:
-
Disaster recovery
Cluster-level failover can automatically and seamlessly transfer the production workload on a primary cluster to one or several backup clusters, which ensures minimum data loss and reduced recovery time.
-
Planned migration
If you want to migrate production workloads from an old cluster to a new cluster, you can improve the migration efficiency with cluster-level failover. For example, you can test whether the data migration goes smoothly in case of a failover event, identify possible issues and risks before the migration.
When cluster-level failover is triggered?
- Automatic cluster-level failover
- Controlled cluster-level failover
Automatic cluster-level failover is triggered when Pulsar clients cannot connect to the primary cluster for a prolonged period of time. This can be caused by any number of reasons including, but not limited to:
-
Network failure
Internet connection is lost.
-
Power failure
Shutdown time of a primary cluster exceeds time limits.
-
Service error
Errors occur on a primary cluster (for example, the primary cluster does not function because of time limits).
-
Crashed storage space
The primary cluster does not have enough storage space, but the corresponding storage space on the backup server functions normally.
Controlled cluster-level failover is triggered when administrators set the switchover manually.
Why does cluster-level failover fail?
Obviously, the cluster-level failover does not succeed if the backup cluster is unreachable by active Pulsar clients. This can happen for many reasons, including but not limited to:
-
Power failure
The backup cluster is shut down or does not function normally.
-
Crashed storage space
Primary and backup clusters do not have enough storage space.
-
If the failover is initiated, but no cluster can assume the role of an available cluster due to errors, and the primary cluster is not able to provide service normally.
-
If you manually initiate a switchover, but services cannot be switched to the backup cluster server, then the system will attempt to switch services back to the primary cluster.
-
Fail to authenticate or authorize between primary and backup clusters, or between two backup clusters.
What are the limitations of cluster-level failover?
Currently, cluster-level failover can perform probes to prevent data loss, but it can not check the status of backup clusters. If backup clusters are not healthy, you cannot produce or consume data.
What are the relationships between cluster-level failover and geo-replication?
The cluster-level failover is an extension of geo-replication to improve stability and robustness. The cluster-level failover depends on geo-replication, and they have some differences as below.
| Influence | Cluster-level failover | Geo-replication |
|---|---|---|
| Do administrators have heavy workloads? | No or maybe. - For the automatic cluster-level failover, the cluster switchover is triggered automatically based on the policies set by users. - For the controlled cluster-level failover, the switchover is triggered manually by administrators. | Yes. If a cluster fails, immediate administration intervention is required. |
| Result in data loss? | No. For both automatic and controlled cluster-level failover, if the failed primary cluster doesn't replicate messages immediately to the backup cluster, the Pulsar client can't consume the non-replicated messages. After the primary cluster is restored and the Pulsar client switches back, the non-replicated data can still be consumed by the Pulsar client. Consequently, the data is not lost. - For the automatic cluster-level failover, services can be switched and recovered automatically with no data loss. - For the controlled cluster-level failover, services can be switched and recovered manually and data loss may happen. | Yes. Pulsar clients and DNS systems have caches. When administrators switch the DNS from a primary cluster to a backup cluster, it takes some time for cache trigger timeout, which delays client recovery time and fails to produce or consume messages. |
| Result in Pulsar client failure? | No or maybe. - For automatic cluster-level failover, services can be switched and recovered automatically and the Pulsar client does not fail. - For controlled cluster-level failover, services can be switched and recovered manually, but the Pulsar client fails before administrators can take action. | Same as above. |
How does cluster-level failover work?
This chapter explains the working process of cluster-level failover. For more implementation details, see PIP-121.
- Automatic cluster-level failover
- Controlled cluster-level failover
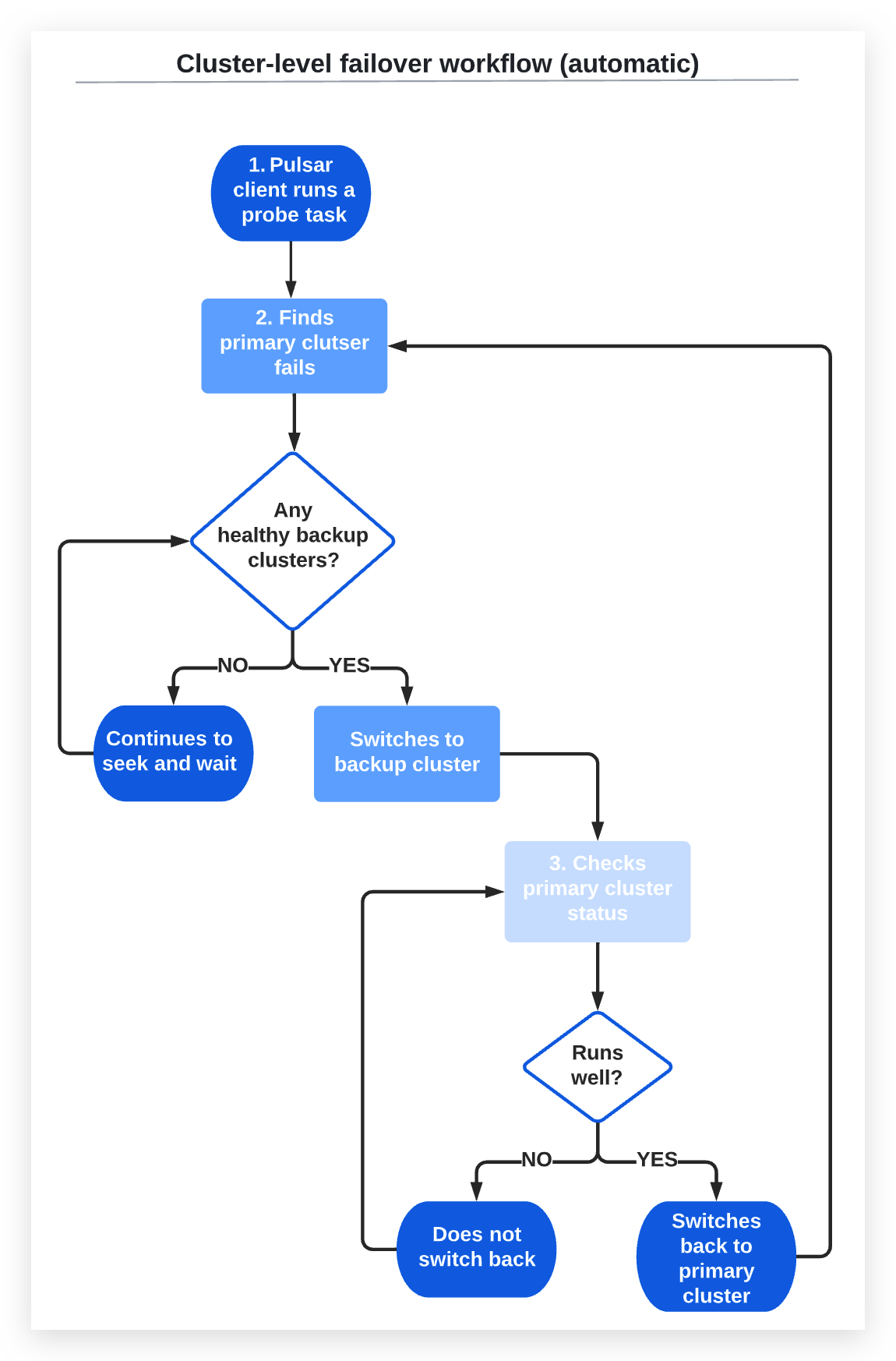
In an automatic failover cluster, the primary cluster and backup cluster are aware of each other's availability. The automatic failover cluster performs the following actions without administrator intervention:
-
The Pulsar client runs a probe task at intervals defined in
checkInterval. -
If the probe task finds the failure time of the primary cluster exceeds the time set in the
failoverDelayparameter, it searches backup clusters for an available healthy cluster.2a) If there are healthy backup clusters, the Pulsar client switches to a backup cluster in the order defined in
secondary.2b) If there is no healthy backup cluster, the Pulsar client does not perform the switchover, and the probe task continues to look for an available backup cluster.
-
The probe task checks whether the primary cluster functions well or not.
3a) If the primary cluster comes back and the continuous healthy time exceeds the time set in
switchBackDelay, the Pulsar client switches back to the primary cluster.3b) If the primary cluster does not come back, the Pulsar client does not perform the switchover.
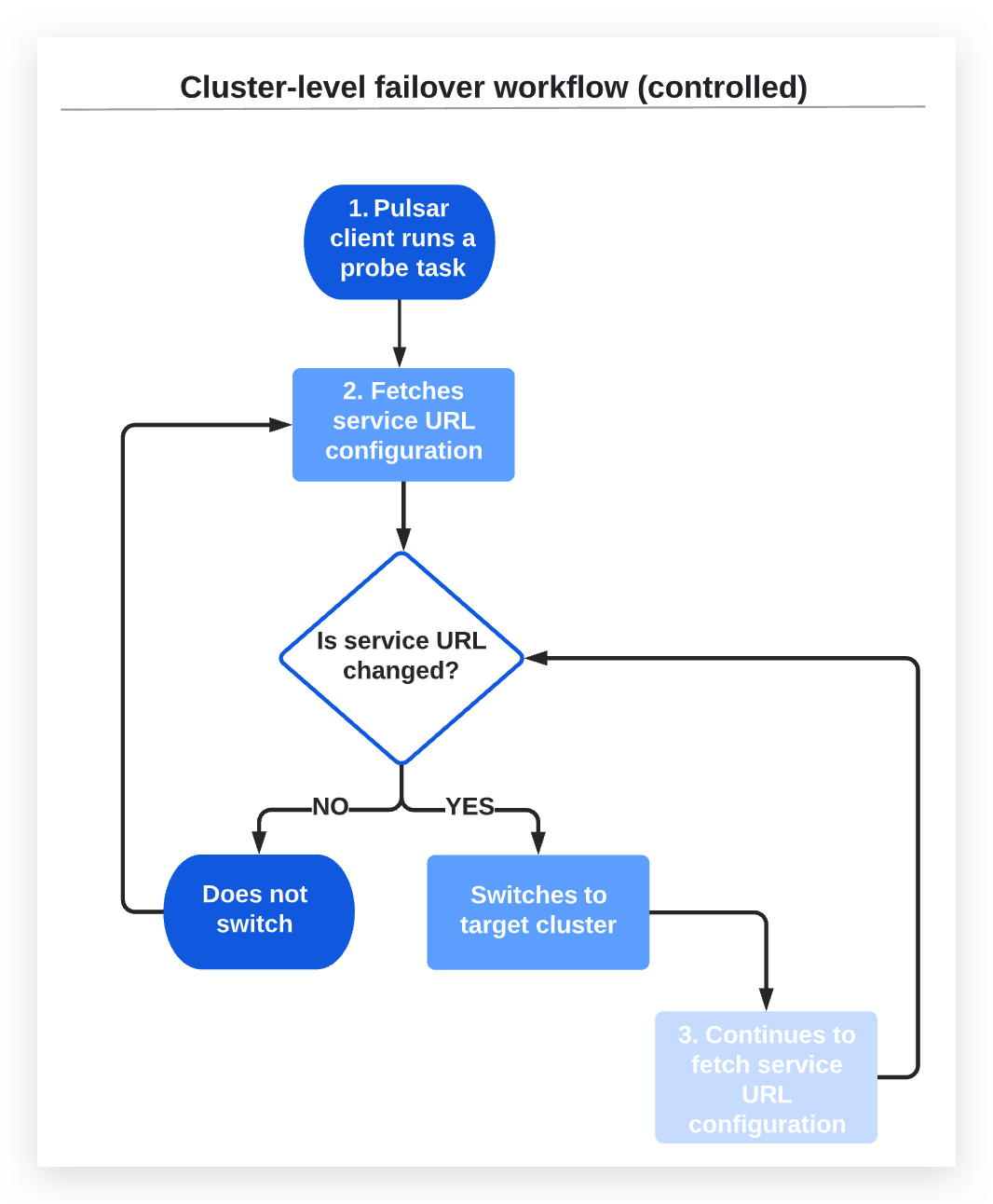
The controlled failover cluster performs the following actions with administrator intervention:
-
The Pulsar client runs a probe task at intervals defined in
checkInterval. -
The probe task fetches the service URL configuration from the URL provider service, which is configured by
urlProvider.2a) If the service URL configuration is changed, the probe task switches to the target cluster without checking the health status of the target cluster.
2b) If the service URL configuration is not changed, the Pulsar client does not perform the switchover.
-
If the Pulsar client switches to the target cluster, the probe task continues to fetch service URL configuration from the URL provider service at intervals defined in
checkInterval.3a) If the service URL configuration is changed, the probe task switches to the target cluster without checking the health status of the target cluster.
3b) If the service URL configuration is not changed, it does not perform the switchover.