ZooKeeper and BookKeeper administration
Pulsar relies on two external systems for essential tasks:
- ZooKeeper is responsible for a wide variety of configuration- and coordination-related tasks.
- BookKeeper is responsible for persistent storage of message data.
ZooKeeper and BookKeeper are both open-source Apache projects.
Skip to the How Pulsar uses ZooKeeper and BookKeeper section below for a more schematic explanation of the role of these two systems in Pulsar.
ZooKeeper
Each Pulsar instance relies on two separate ZooKeeper quorums.
- Local ZooKeeper operates at the cluster level and provides cluster-specific configuration management and coordination. Each Pulsar cluster needs to have a dedicated ZooKeeper cluster.
- Configuration Store operates at the instance level and provides configuration management for the entire system (and thus across clusters). The configuration store quorum can be provided by an independent cluster of machines or by the same machines used by local ZooKeeper.
Deploying local ZooKeeper
ZooKeeper manages a variety of essential coordination- and configuration-related tasks for Pulsar.
Deploying a Pulsar instance requires you to stand up one local ZooKeeper cluster per Pulsar cluster.
To begin, add all ZooKeeper servers to the quorum configuration specified in the conf/zookeeper.conf file. Add a server.N line for each node in the cluster to the configuration, where N is the number of the ZooKeeper node. Here's an example for a three-node cluster:
server.1=zk1.us-west.example.com:2888:3888
server.2=zk2.us-west.example.com:2888:3888
server.3=zk3.us-west.example.com:2888:3888
On each host, you need to specify the ID of the node in each node's myid file, which is in each server's data/zookeeper folder by default (this can be changed via the dataDir parameter).
See the Multi-server setup guide in the ZooKeeper documentation for detailed info on
myidand more.
On a ZooKeeper server at zk1.us-west.example.com, for example, you could set the myid value like this:
$ mkdir -p data/zookeeper
$ echo 1 > data/zookeeper/myid
On zk2.us-west.example.com the command would be echo 2 > data/zookeeper/myid and so on.
Once each server has been added to the zookeeper.conf configuration and has the appropriate myid entry, you can start ZooKeeper on all hosts (in the background, using nohup) with the pulsar-daemon CLI tool:
$ bin/pulsar-daemon start zookeeper
Deploying configuration store
The ZooKeeper cluster configured and started up in the section above is a local ZooKeeper cluster used to manage a single Pulsar cluster. In addition to a local cluster, however, a full Pulsar instance also requires a configuration store for handling some instance-level configuration and coordination tasks.
If you're deploying a single-cluster instance, then you will not need a separate cluster for the configuration store. If, however, you're deploying a multi-cluster instance, then you should stand up a separate ZooKeeper cluster for configuration tasks.
Single-cluster Pulsar instance
If your Pulsar instance will consist of just one cluster, then you can deploy a configuration store on the same machines as the local ZooKeeper quorum but running on different TCP ports.
To deploy a ZooKeeper configuration store in a single-cluster instance, add the same ZooKeeper servers used by the local quorum to the configuration file in conf/global_zookeeper.conf using the same method for local ZooKeeper, but make sure to use a different port (2181 is the default for ZooKeeper). Here's an example that uses port 2184 for a three-node ZooKeeper cluster:
clientPort=2184
server.1=zk1.us-west.example.com:2185:2186
server.2=zk2.us-west.example.com:2185:2186
server.3=zk3.us-west.example.com:2185:2186
As before, create the myid files for each server on data/global-zookeeper/myid.
Multi-cluster Pulsar instance
When deploying a global Pulsar instance, with clusters distributed across different geographical regions, the configuration store serves as a highly available and strongly consistent metadata store that can tolerate failures and partitions spanning whole regions.
The key here is to make sure the ZK quorum members are spread across at least 3 regions and that other regions are running as observers.
Again, given the very low expected load on the configuration store servers, we can share the same hosts used for the local ZooKeeper quorum.
For example, let's assume a Pulsar instance with the following clusters us-west,
us-east, us-central, eu-central, ap-south. Also let's assume, each cluster
will have its own local ZK servers named such as
zk[1-3].${CLUSTER}.example.com
In this scenario we want to pick the quorum participants from few clusters and
let all the others be ZK observers. For example, to form a 7 servers quorum, we
can pick 3 servers from us-west, 2 from us-central and 2 from us-east.
This will guarantee that writes to configuration store will be possible even if one of these regions is unreachable.
The ZK configuration in all the servers will look like:
clientPort=2184
server.1=zk1.us-west.example.com:2185:2186
server.2=zk2.us-west.example.com:2185:2186
server.3=zk3.us-west.example.com:2185:2186
server.4=zk1.us-central.example.com:2185:2186
server.5=zk2.us-central.example.com:2185:2186
server.6=zk3.us-central.example.com:2185:2186:observer
server.7=zk1.us-east.example.com:2185:2186
server.8=zk2.us-east.example.com:2185:2186
server.9=zk3.us-east.example.com:2185:2186:observer
server.10=zk1.eu-central.example.com:2185:2186:observer
server.11=zk2.eu-central.example.com:2185:2186:observer
server.12=zk3.eu-central.example.com:2185:2186:observer
server.13=zk1.ap-south.example.com:2185:2186:observer
server.14=zk2.ap-south.example.com:2185:2186:observer
server.15=zk3.ap-south.example.com:2185:2186:observer
Additionally, ZK observers will need to have:
peerType=observer
Starting the service
Once your configuration store configuration is in place, you can start up the service using pulsar-daemon
$ bin/pulsar-daemon start configuration-store
ZooKeeper configuration
In Pulsar, ZooKeeper configuration is handled by two separate configuration files found in the conf directory of your Pulsar installation: conf/zookeeper.conf for local ZooKeeper and conf/global-zookeeper.conf for configuration store.
Local ZooKeeper
Configuration for local ZooKeeper is handled by the conf/zookeeper.conf file. The table below shows the available parameters:
| Name | Description | Default |
|---|---|---|
| tickTime | The tick is the basic unit of time in ZooKeeper, measured in milliseconds and used to regulate things like heartbeats and timeouts. tickTime is the length of a single tick. | 2000 |
| initLimit | The maximum time, in ticks, that the leader ZooKeeper server allows follower ZooKeeper servers to successfully connect and sync. The tick time is set in milliseconds using the tickTime parameter. | 10 |
| syncLimit | The maximum time, in ticks, that a follower ZooKeeper server is allowed to sync with other ZooKeeper servers. The tick time is set in milliseconds using the tickTime parameter. | 5 |
| dataDir | The location where ZooKeeper will store in-memory database snapshots as well as the transaction log of updates to the database. | data/zookeeper |
| clientPort | The port on which the ZooKeeper server will listen for connections. | 2181 |
| autopurge.snapRetainCount | In ZooKeeper, auto purge determines how many recent snapshots of the database stored in dataDir to retain within the time interval specified by autopurge.purgeInterval (while deleting the rest). | 3 |
| autopurge.purgeInterval | The time interval, in hours, by which the ZooKeeper database purge task is triggered. Setting to a non-zero number will enable auto purge; setting to 0 will disable. Read this guide before enabling auto purge. | 1 |
| maxClientCnxns | The maximum number of client connections. Increase this if you need to handle more ZooKeeper clients. | 60 |
Configuration Store
Configuration for configuration store is handled by the conf/global-zookeeper.conf file. The table below shows the available parameters:
BookKeeper
BookKeeper is responsible for all durable message storage in Pulsar. BookKeeper is a distributed write-ahead log WAL system that guarantees read consistency of independent message logs called ledgers. Individual BookKeeper servers are also called bookies.
For a guide to managing message persistence, retention, and expiry in Pulsar, see this cookbook.
Deploying BookKeeper
BookKeeper provides persistent message storage for Pulsar.
Each Pulsar broker needs to have its own cluster of bookies. The BookKeeper cluster shares a local ZooKeeper quorum with the Pulsar cluster.
Configuring bookies
BookKeeper bookies can be configured using the conf/bookkeeper.conf configuration file. The most important aspect of configuring each bookie is ensuring that the zkServers parameter is set to the connection string for the Pulsar cluster's local ZooKeeper.
Starting up bookies
You can start up a bookie in two ways: in the foreground or as a background daemon.
To start up a bookie in the foreground, use the bookkeeper
$ bin/pulsar-daemon start bookie
You can verify that the bookie is working properly using the bookiesanity command for the BookKeeper shell:
$ bin/bookkeeper shell bookiesanity
This will create a new ledger on the local bookie, write a few entries, read them back and finally delete the ledger.
Hardware considerations
Bookie hosts are responsible for storing message data on disk. In order for bookies to provide optimal performance, it's essential that they have a suitable hardware configuration. There are two key dimensions to bookie hardware capacity:
- Disk I/O capacity read/write
- Storage capacity
Message entries written to bookies are always synced to disk before returning an acknowledgement to the Pulsar broker. To ensure low write latency, BookKeeper is designed to use multiple devices:
- A journal to ensure durability. For sequential writes, it's critical to have fast fsync operations on bookie hosts. Typically, small and fast solid-state drives (SSDs) should suffice, or hard disk drives (HDDs) with a RAIDs controller and a battery-backed write cache. Both solutions can reach fsync latency of ~0.4 ms.
- A ledger storage device is where data is stored until all consumers have acknowledged the message. Writes will happen in the background, so write I/O is not a big concern. Reads will happen sequentially most of the time and the backlog is drained only in case of consumer drain. To store large amounts of data, a typical configuration will involve multiple HDDs with a RAID controller.
Configuring BookKeeper
Configurable parameters for BookKeeper bookies can be found in the conf/bookkeeper.conf file.
Minimum configuration changes required in conf/bookkeeper.conf are:
# Change to point to journal disk mount point
journalDirectory=data/bookkeeper/journal
# Point to ledger storage disk mount point
ledgerDirectories=data/bookkeeper/ledgers
# Point to local ZK quorum
zkServers=zk1.example.com:2181,zk2.example.com:2181,zk3.example.com:2181
#It is recommended to set this parameter. Otherwise, BookKeeper can't start normally in certain environments (for example, Huawei Cloud).
advertisedAddress=
To change the zookeeper root path used by Bookkeeper, use zkLedgersRootPath=/MY-PREFIX/ledgers instead of zkServers=localhost:2181/MY-PREFIX
Consult the official BookKeeper docs for more information about BookKeeper.
BookKeeper persistence policies
In Pulsar, you can set persistence policies, at the namespace level, that determine how BookKeeper handles persistent storage of messages. Policies determine four things:
- The number of acks (guaranteed copies) to wait for each ledger entry
- The number of bookies to use for a topic
- How many writes to make for each ledger entry
- The throttling rate for mark-delete operations
Set persistence policies
You can set persistence policies for BookKeeper at the namespace level.
pulsar-admin
Use the set-persistence subcommand and specify a namespace as well as any policies that you want to apply. The available flags are:
| Flag | Description | Default |
|---|---|---|
-a, --bookkeeper-ack-quorum | The number of acks (guaranteed copies) to wait on for each entry | 0 |
-e, --bookkeeper-ensemble | The number of bookies to use for topics in the namespace | 0 |
-w, --bookkeeper-write-quorum | How many writes to make for each entry | 0 |
-r, --ml-mark-delete-max-rate | Throttling rate for mark-delete operations (0 means no throttle) | 0 |
Example
$ pulsar-admin namespaces set-persistence my-tenant/my-ns \
--bookkeeper-ack-quorum 3 \
--bookkeeper-ensemble 2
REST API
POST /admin/v2/namespaces/:tenant/:namespace/persistence/setPersistence
Java
int bkEnsemble = 2;
int bkQuorum = 3;
int bkAckQuorum = 2;
double markDeleteRate = 0.7;
PersistencePolicies policies =
new PersistencePolicies(ensemble, quorum, ackQuorum, markDeleteRate);
admin.namespaces().setPersistence(namespace, policies);
List persistence policies
You can see which persistence policy currently applies to a namespace.
pulsar-admin
Use the get-persistence subcommand and specify the namespace.
Example
$ pulsar-admin namespaces get-persistence my-tenant/my-ns
{
"bookkeeperEnsemble": 1,
"bookkeeperWriteQuorum": 1,
"bookkeeperAckQuorum", 1,
"managedLedgerMaxMarkDeleteRate": 0
}
REST API
GET /admin/v2/namespaces/:tenant/:namespace/persistence/getPersistence
Java
PersistencePolicies policies = admin.namespaces().getPersistence(namespace);
How Pulsar uses ZooKeeper and BookKeeper
This diagram illustrates the role of ZooKeeper and BookKeeper in a Pulsar cluster:
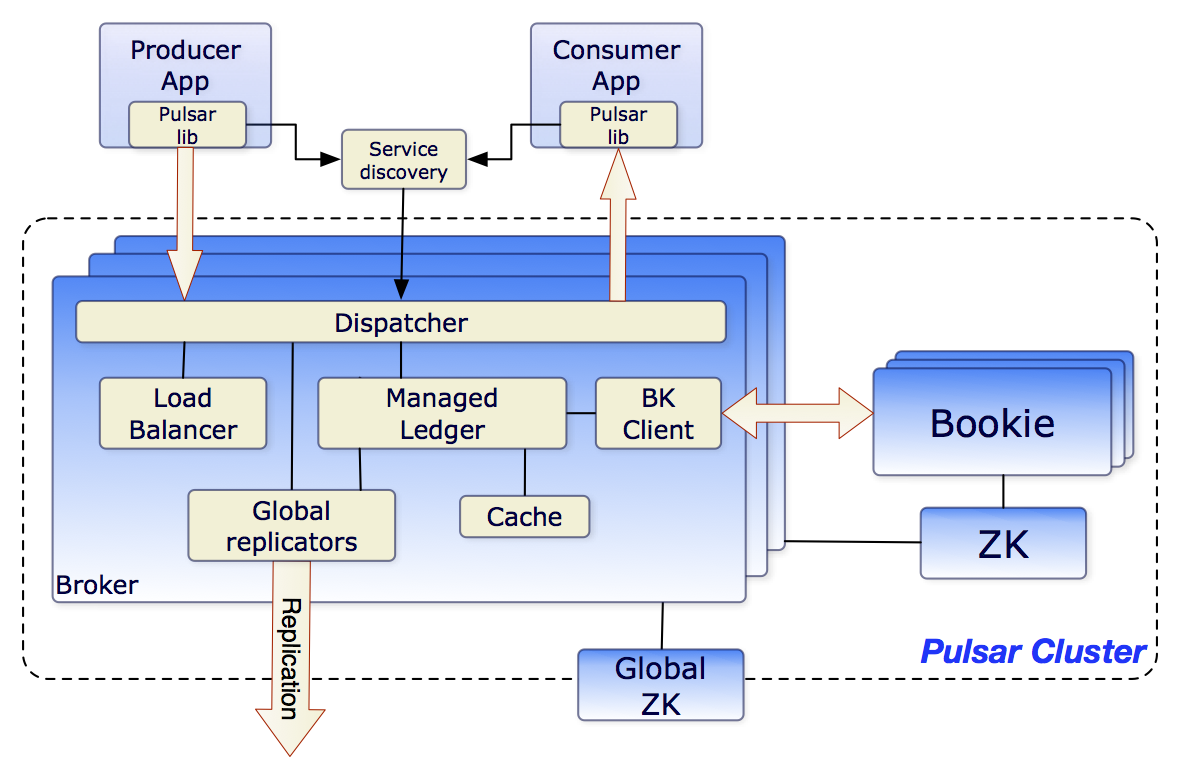
Each Pulsar cluster consists of one or more message brokers. Each broker relies on an ensemble of bookies.