Pulsar SQL Overview
One of the common use cases of Pulsar is storing streams of event data. Often the event data is structured which predefined fields. There is tremendous value for users to be able to query the existing data that is already stored in Pulsar topics. With the implementation of the Schema Registry, structured data can be stored in Pulsar and allows for the potential to query that data via SQL language.
By leveraging Presto, we have created a method for users to be able to query structured data stored within Pulsar in a very efficient and scalable manner. We will discuss why this very efficient and scalable in the Performance section below.
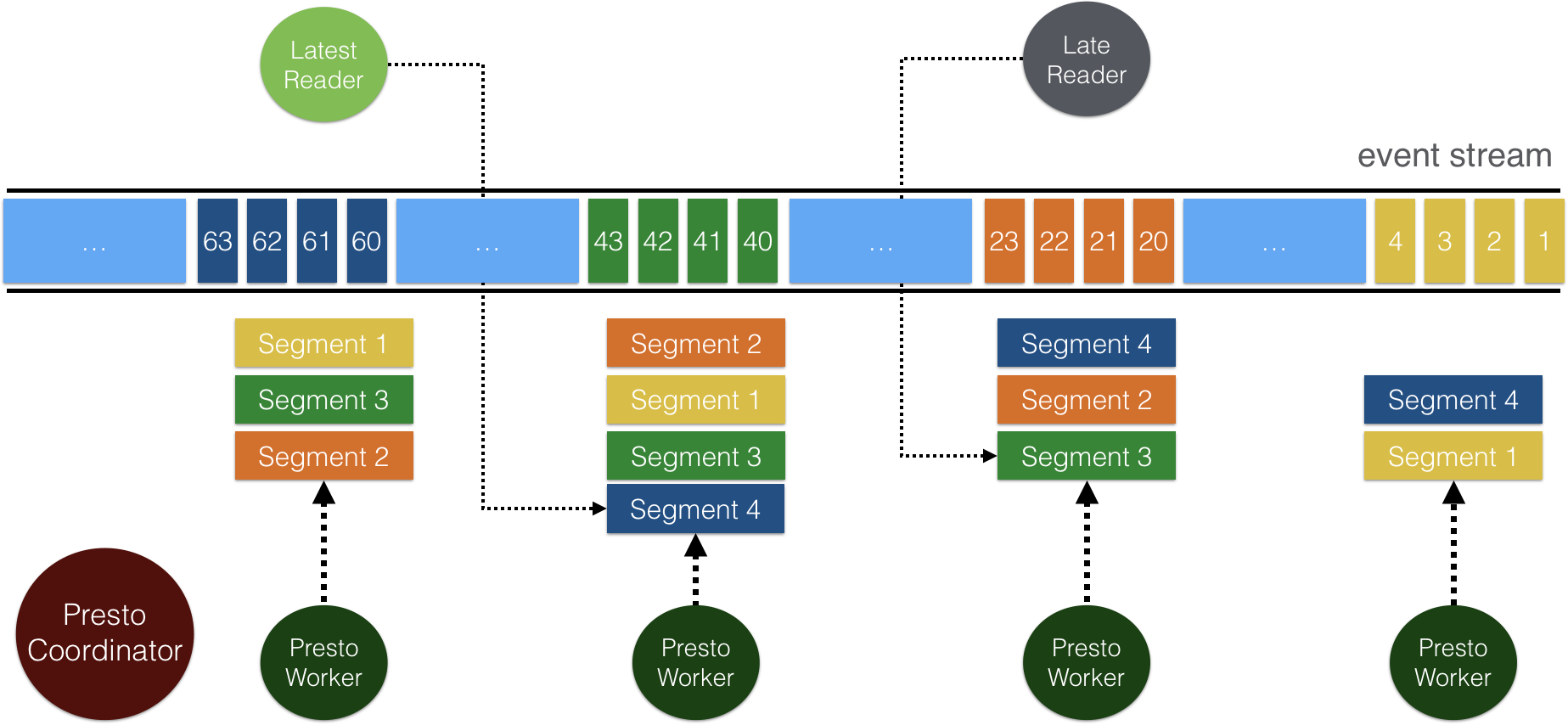
At the core of this Pulsar SQL is the Presto Pulsar connector which allows Presto workers within a Presto cluster to query data from Pulsar.
Performance
The reason why query performance is very efficient and highly scalable because of Pulsar's two level segment based architecture.
Topics in Pulsar are stored as segments in Apache Bookkeeper. Each topic segment is also replicated to a configurable (default 3) number of Bookkeeper nodes which allows for concurrent reads and high read throughput. In the Presto Pulsar connector, we read data directly from Bookkeeper to take advantage of the Pulsar's segment based architecture. Thus, Presto workers can read concurrently from horizontally scalable number bookkeeper nodes.